[คำเตือน: โพสท์นี้ยาวมากกกกกกกกกก]
เดือนเมษาที่ผ่านมา รู้สึกร้อนกันบ้างรึเปล่าครับ?
ใช่ครับ ร้อนระดับที่อาบน้ำเสร็จออกมายืนโง่ๆ แป๊บนึงก็เหงื่อออกอีกแล้ว
ร้อนจนไม่อยากสนใจโลกร้อนแล้วเปิดแอร์ 17c ทิ้งไว้ทั้งวันทั้งคืน แต่ก็ทำไม่ได้เพราะค่าไฟแม่งแพง
แต่เชื่อมั้ยครับ ร้อนขนาดนี้ก็ยังมีคนกล้าจัดงานให้นักวิ่งออกไปวิ่งกันอยู่
งานที่พูดถึงนี่ไม่ใช่วิ่งกะโหลกกะลาห้านาทีสิบนาทีในทุ่งเทเลทับบี้ แต่วิ่งกันสิบชั่วโมง!!
วิ่งตั้งแต่พระอาทิตย์ขึ้นถึงพระอาทิตย์ตก วิ่งให้แดดเลียจนเข่าสึก แถมไม่ได้เพิ่งจัด เพราะจัดมาเป็นปีที่สิบแล้ว!!! (ณ ปี 2019)
“บ้าบอสิ้นดี นอนตากแอร์เย็นๆ สบายกว่าเยอะ ไปวิ่งให้ตับแล่บทำไมวะ”
คิดในใจ แต่ก็สมัครไปทรมานมาสองปีแล้วเหมือนกัน..
งานที่ว่านี้มีชื่อเป็นทางการว่า Suanpruek 99 10-hr ultramarathon จัดในสวนนวมินทร์ภิรมย์ (ชื่องานสวนพฤกษ์แต่จัดสวนนวมินทร์…) เขตบางกะปิ ใครที่ไม่เคยไปสวนนี้ลองนึกภาพตามนะครับ ทางวิ่งยาวๆ รอบบึงน้ำรูปทรงเรียวๆ เหมือนเมล็ดข้าว ระหว่างทางมีต้นไม้นิดๆ หน่อยๆ (ซึ่งแม่งชอบถูกตัดช่วงก่อนงานนี่แหละ) รอบนึงประมาณ 2.1 km ปลายสุดสองด้านมีสะพานให้ได้เก็บความชันนิดหน่อย

Race Information:
กติกาง่ายๆ ในปีล่าสุดของสนามนี้คือวิ่งให้ไม่น้อยกว่า 30 รอบสวนในเวลาสิบชั่วโมง ระยะรวมๆ ประมาณ 63km แค่นั้นก็จะสามารถนับเป็นผู้ที่วิ่งจบแบบเดี่ยว หนีการ DNF ได้ หรือถ้าอยากท้าทายตัวเองก็ลองกดไปให้ได้ Top 100 ก็จะได้เสื้อที่ระลึก ส่วนแบบทีมคือแต่ละทีมมีสมาชิก 4 คน วิ่งคนละ 2 ชม. ครึ่ง ให้ได้ระยะมากที่สุด ลองกดไปดูภาพในเพจงานจะพอจินตนาการออกว่ามันเป็นงานทรมานบันเทิงยังไง
โจทย์วันนี้:
หลายความคิดผ่านหัวไปในสิบชั่วโมงกลางแดด ที่จำได้ชัดๆ คืออยากเลิกวิ่งแล้วกลับไปหาข้อมูลคนที่มาวิ่งงานนี้ว่าเป็นคนแบบไหน โตมายังไง มีปัญหาอะไรรึเปล่าเลยมาเลือกวิธีคลายเครียดแบบนี้.. มี insight อะไรที่เราคาดไม่ถึงจนกลายเป็นเสน่ห์ให้บางคนยอมกลับมาให้แดดเลียสิบชั่วโมงทุกปีรึเปล่า แต่ต้องใช้วิธีที่เข้าใจง่าย ห้ามซับซ้อน ไม่ต้องรู้จักตัวเลขหรือเรียนสถิติอะไรเยอะแยะ
ถึงตอนนี้ผ่านมาประมาณหนึ่งสัปดาห์ พอให้ผิวส่วนที่สัมผัสแดดในวันนั้นเริ่มลอกและผลัดหนังใหม่ ก็เลยได้เวลาขุดคำถามพวกนั้นกลับมาหาคำตอบกันครับ ว่าสนามนี้มีอะไร DD
Data Source:
หลังเข้าสู่ยุคงานวิ่งบูมจนคนไทยหันมาวิ่งแบบพี่ตูนกันค่อนประเทศในช่วงปีสองปีนี้ งานวิ่งที่พอจะได้มาตรฐานเกือบทุกงานก็ใช้ระบบ chip ตรวจสอบเวลาเพื่อให้สามารถเช็คได้ว่านักวิ่งแต่ละคนวิ่งครบระยะที่กำหนด ป้องกันการวาร์ปเข้าเส้นชัยแบบง่ายๆ เหมือนสมัยสิบกว่าปีก่อนที่ต้องรับยางรัดผมตามจุด checkpoint
เลยทำให้หาเวลาวิ่งแต่ละงานได้จากในเว็บสะดวกกว่าเดิมมากทีเดียวครับ งานสวนพฤกษ์ปีล่าสุดนี้ใช้บริการของ raceresult.com พอลองกลับไปหาสถิติปีก่อนๆ พบแหล่งข้อมูลตามนี้
2019 raceresult.com
2018 raceresult.com
2017 งดจัด
2016 sportstats.asia Solo | Team
2015 sportstats.asia Solo | Team
2014 sportstats.asia Solo | Team
2013 และก่อนหน้า หาไม่เจอจริงๆ สันนิษฐานว่าอาจโดนลบไปแล้วหรืออาจไม่ได้ใช้ chiptime
ได้ข้อมูลปุ๊บก็เจอปัญหาปั๊บ ความซวยเริ่มมาเยือนเพราะเว็บพวกนี้ไม่มี api …
raceresult จัดการง่ายหน่อยเพราะเป็นตารางเดียว ก๊อปวางแล้วจบ แต่ sportstats นั้นมีการแบ่งหน้าไว้ ก็ลองไปแง้มๆ หลังบ้านดู พอเห็นว่าเป็น Java Stack ที่ใช้ SOAP ajax ก็ทิ้งความคิดที่จะทำ web crawler เท่ๆ ไปทันที ขออนุญาตงานหยาบก๊อปมือเลยละกัน ไม่ถึงสิบนาทีเสร็จหมดห้าปี
ถ้าใครสนใจอยากได้ data ไปลองเล่น ก็ไปขอก๊อปจากผมที่สวนพฤกษ์ปีหน้าได้…
หลอกๆ แจกเลยครับไม่ต้องเสียเวลาโหลด Raw Data เลย!
Data Wrangling:
ชอบคำว่า Data Wrangling ดูเท่กว่า data cleaning เยอะเลย
เก็บ Data มาแล้วก็ลองเปิดไล่ดูครับ เจอประเด็นที่น่าสนใจเพียบ ถ้าลองเปิด Raw Data ข้างบนดูตามมาจะเห็นภาพมากขึ้น
- ไม่รู้ว่าการเปลี่ยน platform ไปเรื่อยๆ มีผลต่อรูปแบบการเก็บข้อมูลรึเปล่า แต่ metadata ของ dataset ที่ได้มาแต่ละอันมี consistency ค่อนข้างต่ำ อย่างเช่นปี 2014 มี split time ซึ่งปกติจะใช้กับจุด checkpoint ทุกๆ 10 km ของงาน full marathon หรือระยะ 5km ของงาน mini marathon แต่งานนี้มันไม่ระยะจำกัดดดดด ก็ไม่เข้าใจว่าใส่มาทำมะเขืออะไร ในขณะเดียวกันปี 2014 นี่เองก็ดันไม่มีจำนวนรอบ ซึ่งต้องใช้ตัดสินการเป็น finisher… ก็ไม่รู้ว่าตอนนั้นเค้าตัดสินกันยังไงเหมือนกัน

Data Inconsistency #1 2014 มี Split Time Data Inconsistency #2 2015 มี Lap Count ปกติ หมายความว่าถ้าจะเล่นข้อมูลจำนวนรอบก็ต้องตัดปี 2014 ทิ้งไปก่อนเลย.. แล้วจะเก็บมาทำไมฟระะะะ
- นอกจากเรื่องการนับรอบที่ชวนปวดหัวในปีแรกแล้ว ปี 2018 ยังมีการใช้ category ที่ไม่เหมือนชาวบ้านด้วย จากที่ปกติปีอื่นๆ แบ่งกลุ่มนักวิ่งเป็น ชาย / หญิง / อาวุโส (50+) / Team Relay ปี 2018 ดันแบ่งเป็นแค่ Solo กับ Team…
Data Inconsistency #3 2018 มี Category แค่ Solo กับ Team Data Inconsistency #3 2018 มี Category แค่ Solo กับ Team เช่นเคยครับ ถ้าจะดู ranking ผู้ชายผู้หญิงก็ต้องขอนิมนต์ปี 2018 ออกไปรอนอกโบสถ์ก่อนเช่นกัน
- สุดท้าย ปี 2019 ทีมงานข้อมูลน่าจะเพิ่งนึกได้ เลยแปะ Year of Birth ของนักวิ่งเดี่ยวมาให้ด้วย.. แต่เนื่องจากปีก่อนๆ มันไม่มี ดังนั้นถ้าจะใช้ก็เปรียบเทียบได้แค่ในปีเดียวนี้แหละ..
Data Inconsistency #4 2019 มี Year-of-Birth

เลือก column เท่าที่จำเป็น ได้แก่ BIB / ชื่อ / Category / Rank / จำนวนรอบ / Total Time แล้วตัดแต่ง sheet อีกรอบจนได้ CSV พร้อมเอาไปใช้ต่อ โหลดได้เลย!
จากที่เห็นว่า CSV นั้นแยกแต่ละ worksheet ออกเป็นไฟล์ของตัวเอง
การ import data เข้า R วันนี้เลยขอเสนอกระบวนท่า “บรรทัดเดียวจบทั้ง folder”
setwd('Data/') # Solo Data temp <- list.files(path="Solo", pattern = "*.csv") temp <- sub("^", "Solo/", temp ) soloFiles = lapply(temp, function(i){ read.csv(i, header=TRUE, stringsAsFactors = FALSE) }) # Team Data temp <- list.files(path="Team", pattern = "*.csv") temp <- sub("^", "Team/", temp ) teamFiles = lapply(temp, function(i){ read.csv(i, header=TRUE, stringsAsFactors = FALSE) }) |
* อย่าลืม setwd ให้ถูกด้วย
จะได้ list ของ data จากแต่ละไฟล์มาอยู่รวมกัน หลังจากนี้จะเปลี่ยนไปใช้ data frame หรืออะไรก็แล้วแต่ถนัด แต่ด้วยนิสัยขี้เกียจ เราก็จะไปกันต่อด้วยอะไรที่มีนี่แหละ

ก่อนอื่นเราอยากรู้จำนวนคนวิ่งแต่ละปี เพื่อยืนยันว่าประเทศเราเข้าสู่ยุควิ่งแบบพี่ตูน โดยสมบูรณ์แล้ว
countBIB <- data.frame(c(length(soloFiles[[1]]$BIB), length(soloFiles[[2]]$BIB), length(soloFiles[[3]]$BIB), length(soloFiles[[4]]$BIB), length(soloFiles[[5]]$BIB))) colnames(countBIB) <- "Year" rownames(countBIB) <- c(2014, 2015, 2016, 2018, 2019) x <- as.numeric(rownames(countBIB)) y <- as.numeric(countBIB$Year) fit <- lm(y~x) co <- coef(fit) plot( y ~ x, xlab="Year", ylab="Runners", pch=16, cex.lab = 0.6, cex.axis = 0.6, ylim=c(200,1000), main="Suanpruek 99 Participants" ) abline(fit, col="blue", lwd=2) text( x, y, y, cex=0.7, col="red", pos = 1 ) |
เริ่มต้นด้วยการนับ BIB ทั้งหมดของแต่ละปีออกมา สร้าง linear model ง่ายๆ ดู trend line แล้วก็ plot ทั้งหมดออกมาได้ตามนี้
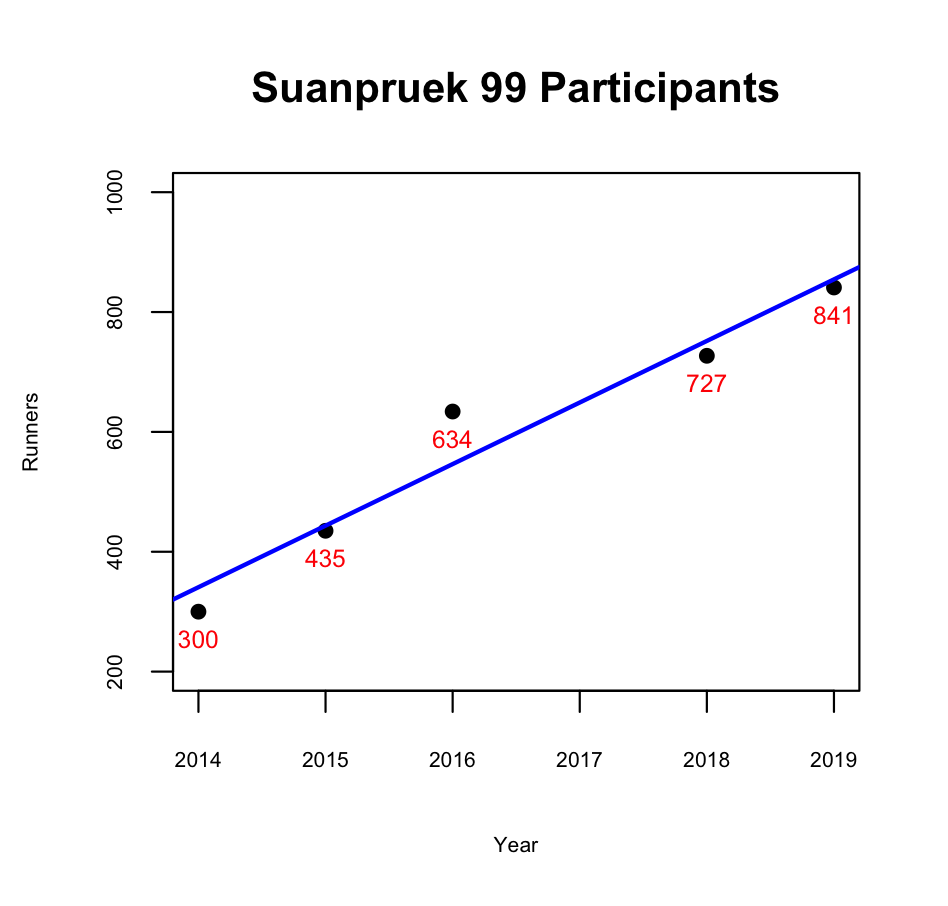
ก็ชัดเจนนะครับ..
หลังจากนั้นก็มารู้จัก top 5 ของสนามแต่ละปีกันหน่อย
head(soloFiles[[1]]) head(soloFiles[[2]]) head(soloFiles[[3]]) head(soloFiles[[4]]) head(soloFiles[[5]]) |
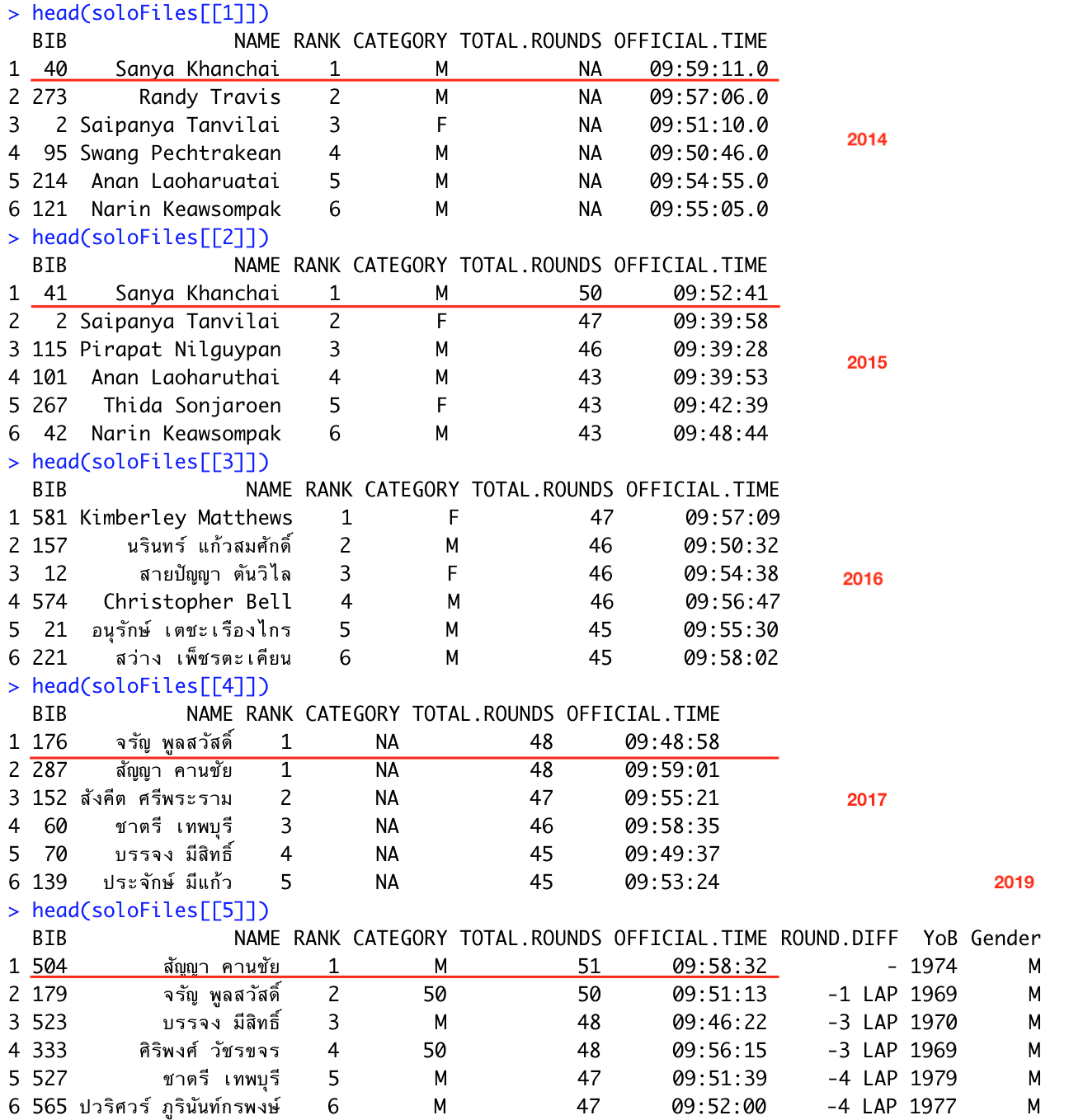
พี่ป้อม สัญญา คานชัย แทบจะผูกปิ่นโตเป็นแชมป์ของสนามนี้เกือบทุกปีจริงๆ ถ้ายังไม่รู้จักแกลองดูคลิปที่รายการ Runner’s Journey เพิ่งไปสัมภาษณ์แกมาครับ
Working Time:
ถึงตอนนี้หลายๆ คนน่าจะขมวดคิ้ว “ไหนวะ DD อยากกินดังกิ้นโดนัทเหรอ?”
D ตัวแรกมาแล้วครับ
Distribution
จากช่วงสำรวจข้อมูลเราเห็นจำนวนนักวิ่งที่เพิ่มมาแต่ละปี
“เรารู้อะไรได้มากกว่านั้นมั้ยฮึ?”
เหรียญอีกด้านของการมีตำแหน่ง Finisher คือ DNFers หรือนักวิ่งที่วิ่งไม่ครบระยะในเวลาที่กำหนด แต่ถ้าให้มานับจำนวนเฉยๆ ว่าแต่ละปีมีคนจบเท่าไหร่มันก็จะง่ายไป งานสวนพฤกษ์นี้มีจำนวนรอบเป็นตัววัด ดังนั้นข้อมูลที่เรามีน่าจะพอบอกเราได้บ้างว่าคนที่วิ่งไม่จบนั้นมีสัดส่วนเท่าไหร่ที่ถอดใจไปกลางทาง และอีกเท่าไหร่ที่อัดไปจนหมดเวลาหน้าเส้นชัย
การดูการกระจายตัวของนักวิ่งด้วย Histogram ให้คำตอบนี้ได้ครับ ไปต่อเลย
# remove NA rows from total rounds soloRound.2 <- soloFiles[[2]]$TOTAL.ROUNDS[!is.na(soloFiles[[2]]$TOTAL.ROUNDS)] soloRound.3 <- soloFiles[[3]]$TOTAL.ROUNDS[!is.na(soloFiles[[3]]$TOTAL.ROUNDS)] soloRound.4 <- soloFiles[[4]]$TOTAL.ROUNDS[!is.na(soloFiles[[4]]$TOTAL.ROUNDS)] soloRound.5 <- soloFiles[[5]]$TOTAL.ROUNDS[!is.na(soloFiles[[5]]$TOTAL.ROUNDS)] teamRound.2 <- teamFiles[[2]]$TOTAL.ROUNDS[!is.na(teamFiles[[2]]$TOTAL.ROUNDS)] teamRound.3 <- teamFiles[[3]]$TOTAL.ROUNDS[!is.na(teamFiles[[3]]$TOTAL.ROUNDS)] teamRound.4 <- teamFiles[[4]]$TOTAL.ROUNDS[!is.na(teamFiles[[4]]$TOTAL.ROUNDS)] teamRound.5 <- teamFiles[[5]]$TOTAL.ROUNDS[!is.na(teamFiles[[5]]$TOTAL.ROUNDS)] # Solo par(mfrow=c(2,2)) hist(soloRound.2, breaks=max(soloRound.2), main = "2015", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(soloRound.3, breaks=max(soloRound.3), main = "2016", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(soloRound.4, breaks=max(soloRound.4), main = "2018", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(soloRound.5, breaks=max(soloRound.5), main = "2019", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") # Team par(mfrow=c(2,2)) hist(teamRound.2, breaks=max(teamRound.2), main = "2015", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(teamRound.3, breaks=max(teamRound.3), main = "2016", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(teamRound.4, breaks=max(teamRound.4), main = "2018", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(teamRound.5, breaks=max(teamRound.5), main = "2019", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") |
plot histogram ออกมา 4 ปีที่มีข้อมูลจำนวนรอบใช้ breaks แบ่งซอยจำนวนแท่งออกตาม maximum laps ของปีนั้นๆ จะได้เห็นชัดๆ ว่าคนส่วนใหญ่ไปกองกันที่แถวไหน
ประเภทเดี่ยว
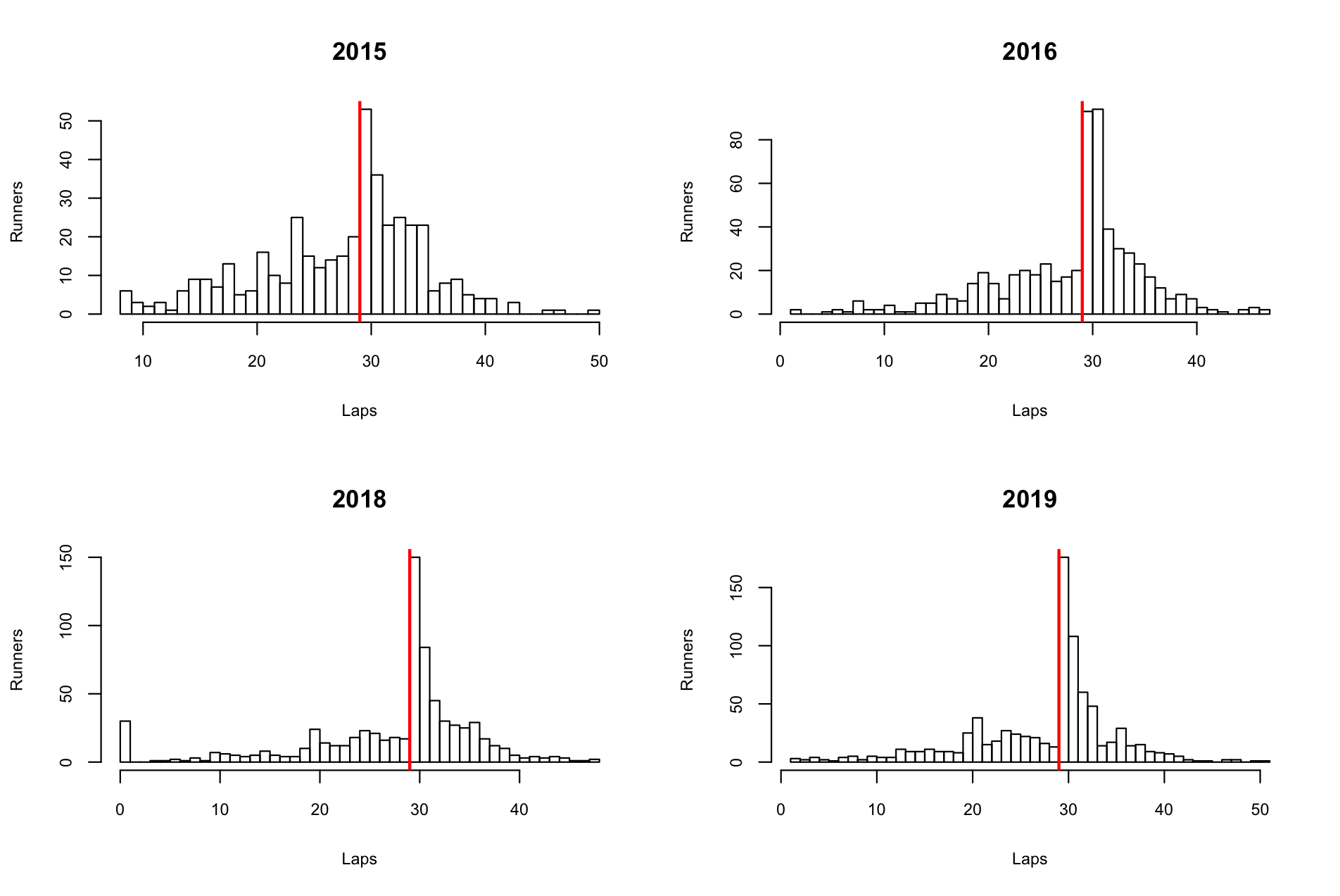
ออกมาสวยจนเกือบเป็น Normal Distribution อยู่เหมือนกัน
“แล้วไงต่อ จากกราฟนี้รู้อะไรบ้าง?”
มาลองวิเคราะห์กันตามจุดที่มีลูกศรชี้…
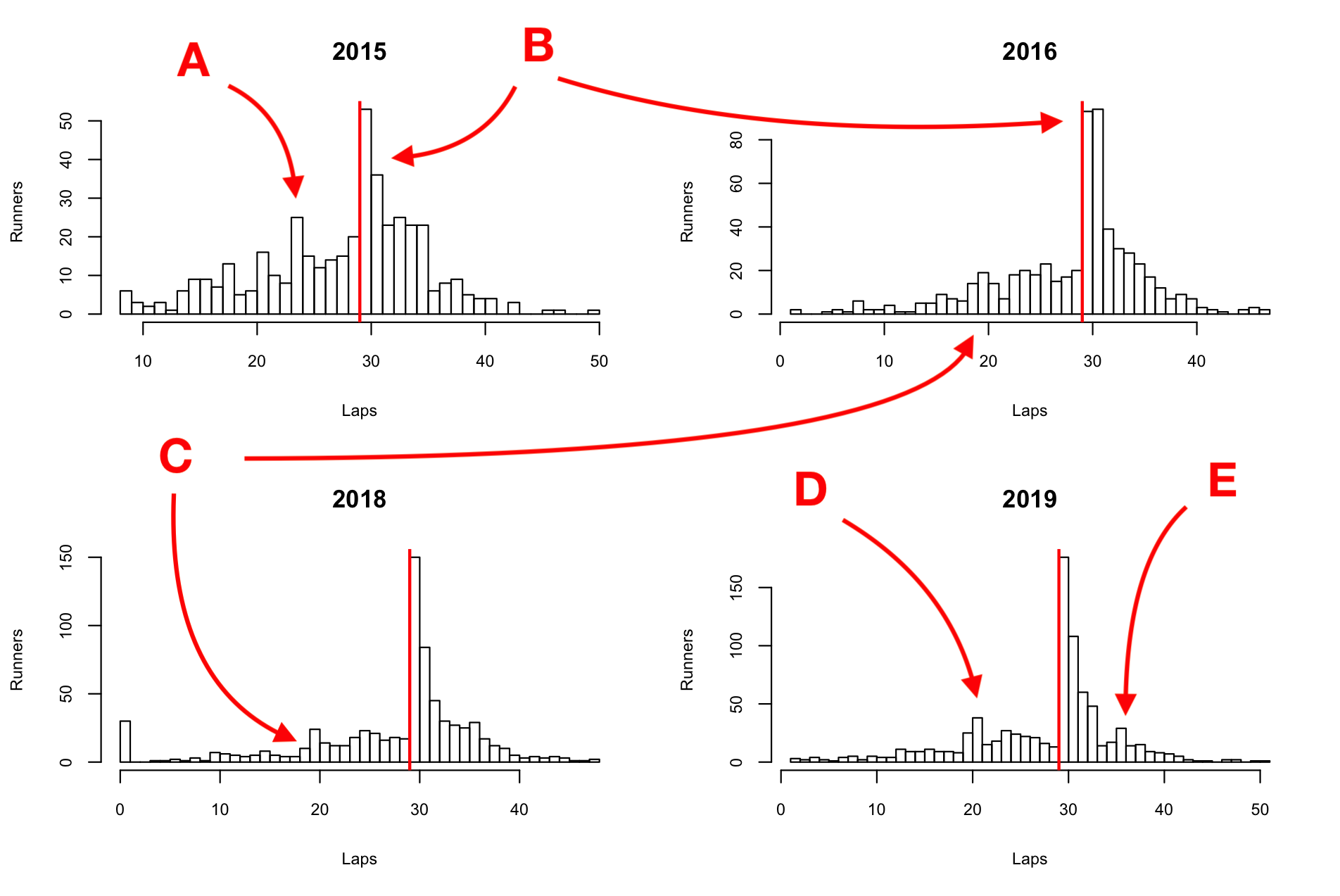
* พอนึกภาพออกว่าเส้นที่สูงสุดถือเป็นประชากรส่วนใหญ่ของงานคือกลุ่มคนที่วิ่งจบ 30 รอบพอดี ใช้แท่งนี้เป็นจุดอ้างอิงละกัน จุดที่น่าสนใจส่วนมากจะอยู่ทางซ้ายของกราฟ เพราะทางขวาเป็นดินแดนของทวยเทพอัลตร้า มีแต่คนที่วิ่งไปคุยกับพระเจ้าไป เลยไม่ค่อยน่าสนใจเท่าไหร่ แถมบางปีเป็นครึ่ง Bell Curve สมบูรณ์ได้อีก ดูโลกมนุษย์ทางซ้ายสนุกกว่าเยอะ
** ดู Histogram แล้วนึกถึงกราฟความชันหรือความสูงสะสมที่ชอบออกมาในงานวิ่งเทรล เดี๋ยวตอนหน้าๆ ค่อยหาสถิติเทรลซักงานมาเล่นละกันนะครับ
บทวิเคราะห์เซียนสนามซ้อม
A) ปี 2015 มีเขาลูกเล็กๆ ลูกนึงตั้งขึ้นมาตรงนี้ ถ้าดูแค่ฝั่งซ้ายก็จะเห็นว่าแท่ง A เป็นภูเขาที่สูงที่สุดในโลกมนุษย์
“แล้วหมายความว่าไง?” การที่มีนักวิ่ง 20 กว่าคนหรือ 5% ของงานในปีนั้นมากองที่ประมาณ 25 รอบสวน แปลว่าระยะ threshold ที่นักวิ่งส่วนใหญ่จะถอดใจไม่ไปต่ออยู่ที่ประมาณ 50km ซึ่งเกินระยะ full-marathon ไปพอสมควร ทดข้อมูลนี้ไว้ในใจก่อนนะครับ
B) ทีนี้ลองมาเทียบจำนวน finisher ระหว่างปี 2015 กับ 2016 ความน่าสงสัยคือปี 2015 มีนักวิ่งที่จบ 30 รอบแล้วไม่ต่อเกิน 50 คน (~12.5%) ในขณะที่ที่ 2016 ดันมีคนวิ่ง 31 รอบเกิน 80 คน! จำนวนพอๆ กับคนที่วิ่งแค่ 30 รอบ จนอดคิดไม่ได้ว่านี่อาจปีในตำนานที่สนามไฟดับจนใช้ผลจากตัวนับรอบไม่ได้ เลยต้องมีการเทียบ finisher จากระยะในนาฬิกาของแต่ละคน หรือพูดง่ายๆ ว่านี่อาจเป็นปีที่มีการนับผลเพี้ยนนั่นเอง… อีกหลักฐานที่อาจยืนยันเรื่องนี้คือความเรียงตัวอย่างสวยเป็นครึ่ง normal distribution ของกราฟฝั่งขวาครับ เพราะต่อให้ข้อมูลกระจายตัวดีขนาดไหนก็มีโอกาสสวยขนาดนี้ยากกกกกก
C) จากข้อ A ที่ทดไว้เมื่อกี๊ พอมาเป็นปี 2016 และ 2018 จะเห็นว่าภูเขา threshold ลูกแรกถอยร่นมาอยู่ที่ 20 รอบครับ.. อาจตีความอย่างหยาบๆ ได่ว่านักวิ่งจำนวนหนึ่งในปีนี้ถอดใจกันไวขึ้นกว่าปี 2015 ที่ระยะประมาณ 42km หรือที่ได้ยินบ่อยๆ ในวันงานว่า “จบฟูลกูพอละนะ ร้อนชิบหxย”
D) ปี 2016 และ 2018 มี threshold แรกที่ 42km แต่ก็ยังมีนักวิ่งอีกจำนวนพอๆ กันตัดสินใจหยุดวิ่งที่ 50km เหมือนปี 2015 (จำนวนเกือบจะเท่ากันคือประมาณ 2o กว่าคน แต่คิดเป็นสัดส่วนน้อยกว่าเมื่อเทียบกับนักวิ่งทั้งหมดในปีนั้น) แต่ในจุด D ของปี 2019 เห็นชัดเจนว่า threshold 50km ได้กลายเป็นอดีตไปแล้วครับ ระยะถอดใจถอยมาอยู่ที่ 42km อย่างสมบูรณ์ด้วยกลุ่มนักวิ่ง 40 กว่าคน คิดเป็นเกือบๆ 5% เหมือนระยะ 50km ของปี 2015 แต่เข้าใจเหตุผลของทุกคนนะ ปีนี้แม่งร้อนเกินเหตุไปจริงๆ
E) สุดท้ายเป็นเรื่องที่ผมก็ไม่ค่อยแน่ใจ แต่เหมือนดินแดนแห่งเทพก็มีภูเขา threshold อะไรซักอย่าง.. ทำไมนักวิ่งกลุ่มนึงพยายามไปให้มากกว่าจำนวนรอบนี้ ถ้าให้เดาตามความเป็นไปได้ ผมคิดว่านี่คือ lower limit ของ Top 100 ที่จะได้เสื้อที่ระลึกครับ คนสุดท้ายที่ได้เสื้อน่าจะต้องจบอยู่ที่ 36-37 รอบ เป็นระยะทาง 75km++ แน่นอน!
ประเภททีม
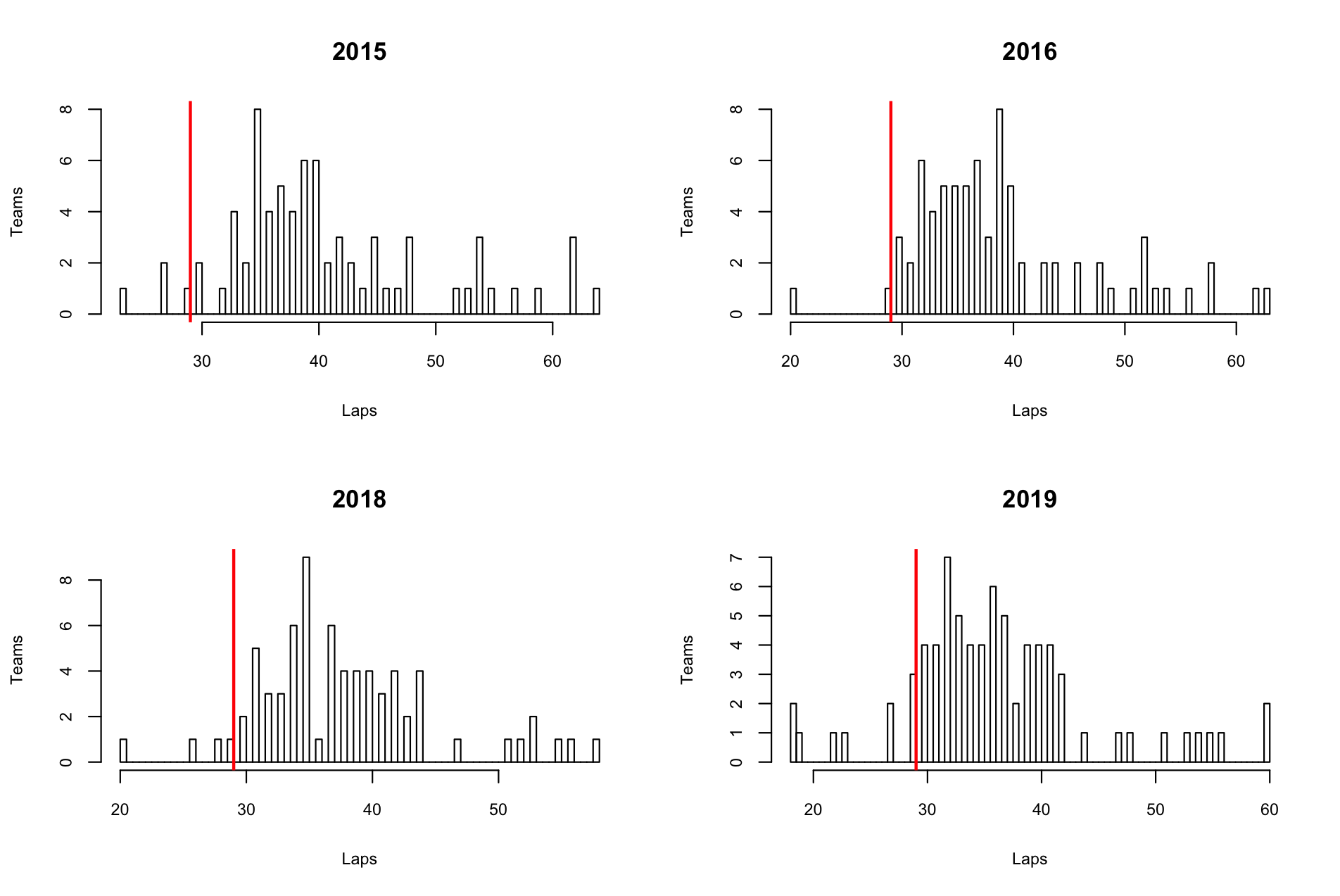
จุดที่แตกต่างอย่างเห็นได้ชัดของประเภททีมคือ กราฟเบ้ขวาเว้ย แปลว่า median ค่อนมาทางขวา ในขณะที่ mean ไปทางซ้าย ต่างจากกราฟประเภทเดี่ยวด้านบนที่ค่อนข้างกระจายสม่ำเสมอ สาเหตุที่ Right Skewed เพราะการวิ่งแบบทีมทำให้นักวิ่งยังสดและทำรอบได้เยอะ ส่วนใหญ่ก็จะแตะอยู่ที่ประมาณ 8-10 รอบต่อผลัด ซึ่งจะทำให้จำนวนรอบรวมมากกว่าเกณฑ์ขั้นต่ำของประเภทเดี่ยวตามเส้นสีแดงอยู่ดี
กลุ่มทวยเทพในประเภททีมจึงไม่ใช่ครึ่งขวาของกราฟ แต่เป็นกลุ่ม 10 ทีมสุดท้ายที่อยู่ฝั่งปลายกราฟที่ถีบจำนวนรอบในแต่ละผลัดขึ้นมาเกิน 12.5 รอบ ถึงจะมีสิทธิ์ลุ้น Top 10 ซึ่งทีมที่ฉีกมาได้ไม่เกิน 10 ทีมพวกนี้แหละครับ ตัวการที่ทำให้กราฟเบ้ขวา (ทำหน้าที่เหมือนเพื่อนตัวเนิร์ดที่ชอบดึงมีนในเซคขึ้นและทำให้พวกเราตกมีนไปไกลกว่าเดิม)
ที่น่าสังเกตอีกอย่างคือ ปี 2019 นี้มีจำนวนทีมที่ไม่ผ่านแม้แต่ 30 รอบอยู่เกือบ 10 ทีม ต่างจากปีก่อนๆ ที่ยังไงก็ไม่เกิน 5 ทีม นับเป็นการยืนยันอีกครั้งว่าปีนี้ “ร้อนชิบหxยเลยโว้ยยยย”

D ตัวแรกหมดแล้ว เห็นการกระจายตัวคร่าวๆ ของงานนี้พอสมควร มาถึง D ตัวที่สอง
Deviation
นอกจากการอ่าน distribution ง่ายๆ ด้วย histogram แล้ว D ตัวที่สองที่เรามองหาก็คือการดู Deviation หรือการดูความเบี่ยงเบนของข้อมูล จะได้รู้ว่างานสวนพฤกษ์แต่ละปีนักวิ่งเกาะกลุ่มกันจริงๆ ขนาดไหน

# Solo par(mfrow=c(1,1)) TOTAL.ROUNDS <- list( soloRound.2, soloRound.3, soloRound.4, soloRound.5 ) boxplot( TOTAL.ROUNDS, names = c("2015", "2016", "2018", "2019"), las = 2 ) # Team par(mfrow=c(1,1)) TOTAL.ROUNDS <- list( teamRound.2, teamRound.3, teamRound.4, teamRound.5 ) boxplot( TOTAL.ROUNDS, names = c("2015", "2016", "2018", "2019"), las = 2 ) |
ได้ผลทั้งสองประเภทตามด้านล่าง
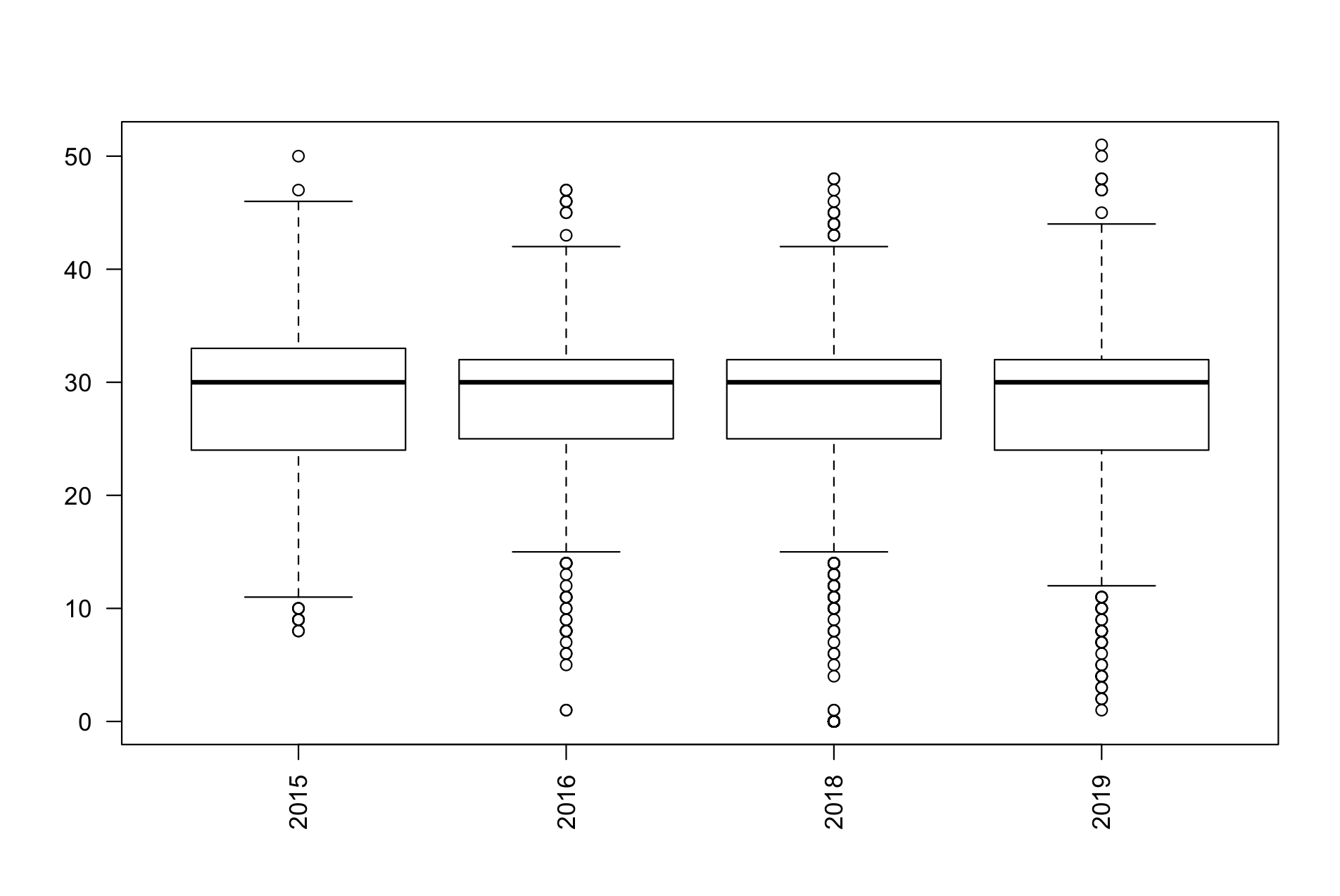
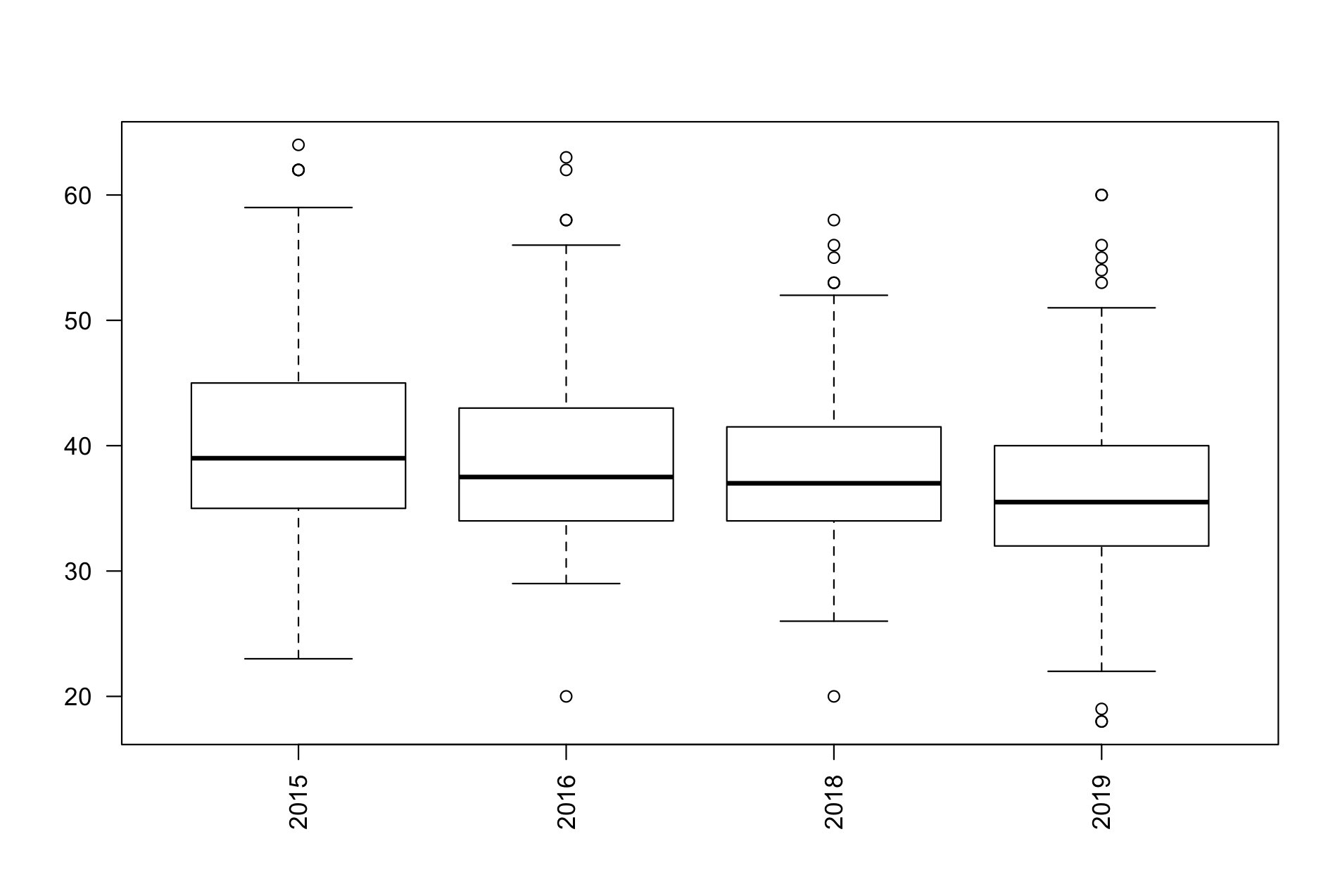
“แล้วมันบอกอะไร?”
กล่องสี่เหลี่ยมในแต่ละปี (เรียกว่า box) คือ 50% ของข้อมูลทั้งหมด ในขณะที่เส้นยืดๆ (เรียกว่า whisker เหมือนหนวดแมลงสาบ) มีความยาวแต่ละด้านเป็น 25% ของข้อมูล ส่วนจุดกลมๆ นอก the wall นั้นคือ outlier
ดู outlier นอก the north wall สิครับ นั่นแหละ white runner วิ่งยังกะซอมบี้…
การทำ boxplot เพื่อดู deviation นั้นจะมีประโยชน์กว่า histogram เมื่อเรามี dataset มากกว่า 1 set ให้เปรียบเทียบกัน ถ้าใช้ histogram นี่ก็ต้องเอามาซ้อน layer ใช้ ggplot วุ่นวายไปหน่อย โยนลง boxplot เทียบกันง่ายๆ จบเลย
“โอเค แล้วตกลงมันบอกอะไร?”
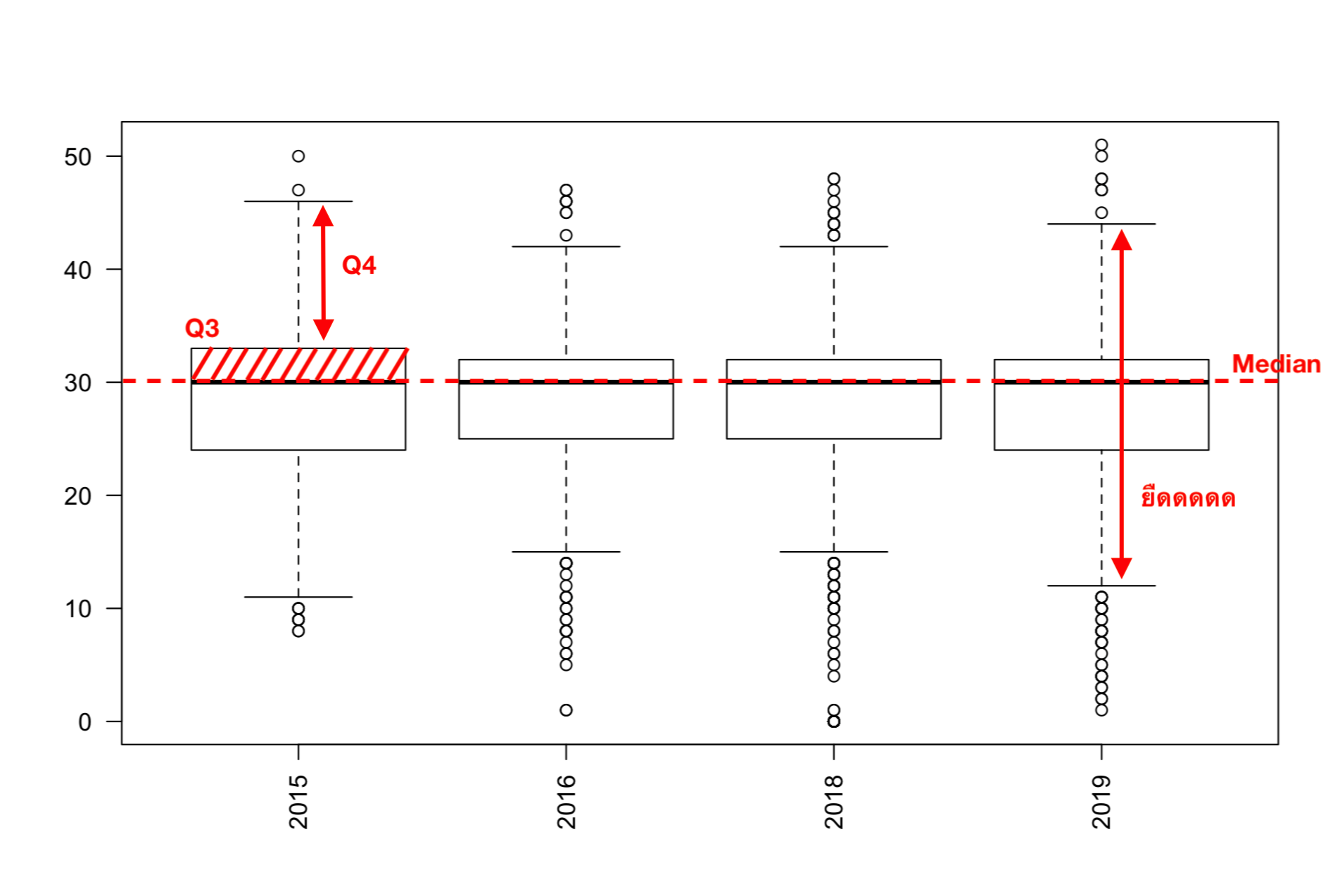
เริ่มที่ประเภทเดี่ยวก่อนเราจะเห็นว่า median ของทั้งสี่ปีอยู่ในช่วงเดียวกันคือ 30 รอบแต่มีแค่ปี 2015 ที่ Q3 หนากว่าปีอื่นๆ รวมถึง Q4 ที่ยืดไปมากสุดด้วย พูดง่ายๆ คือเป็นปีที่ SD กว้าง มีคนทั้งวิ่งได้จำนวนรอบน้อยสุดและมากสุดอยู่ด้วยกัน ปต่ปี 2016/2018 นักวิ่งค่อนข้างเกาะกลุ่มและ SD แคบ ก่อนจะกลับมาเริ่มยืดอีกครั้งในปี 2019 ที่มีจำนวนนักวิ่งเยอะสุด
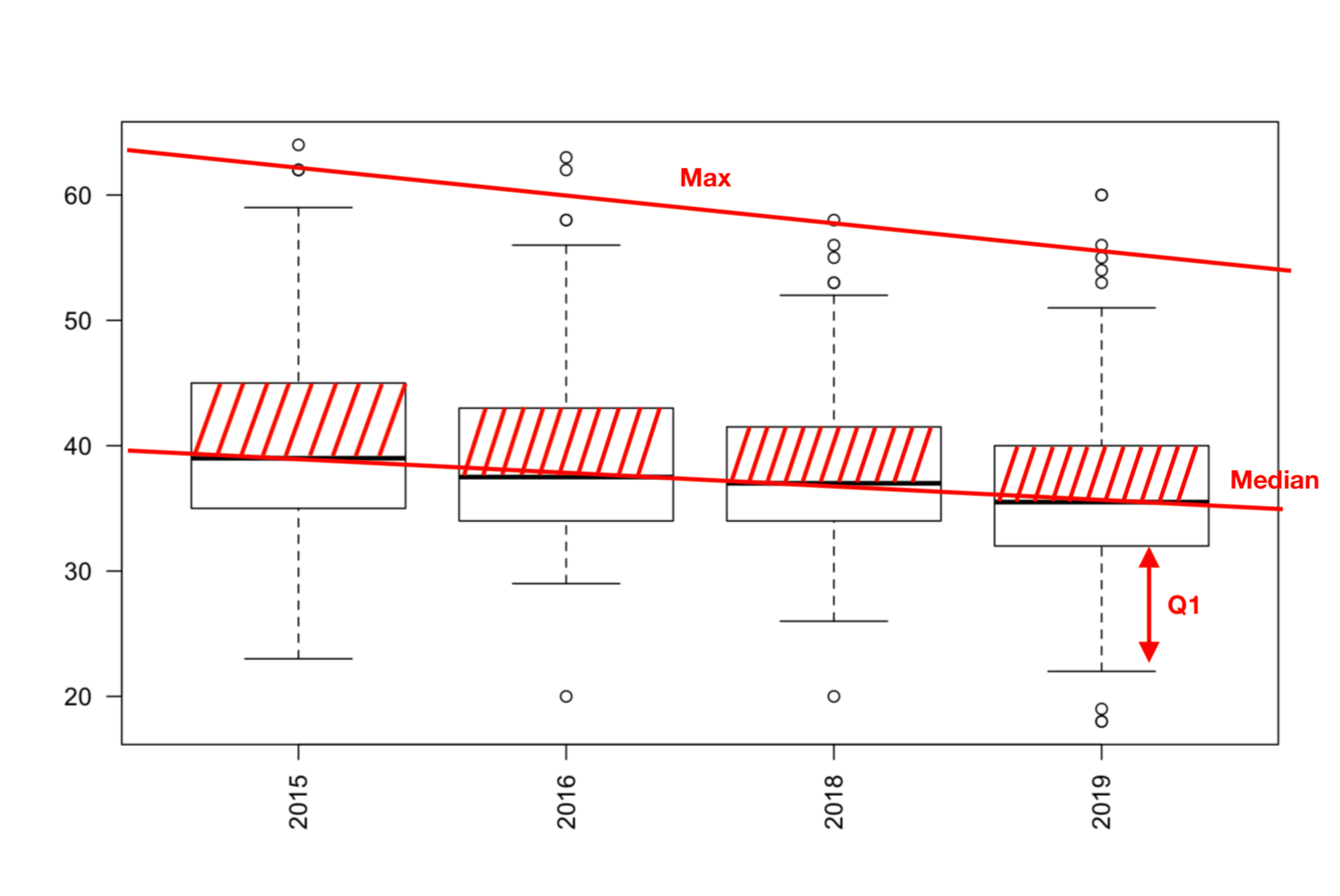
สำหรับประเภททีมทุกปีมี Q3 กว้างกว่า Q2 แปลว่าทีมส่วนใหญ่ในก้อน 50% รอบๆ median นั้นวิ่งเกิน median ขึ้นไป ในขณะที่ Q1 ของปี 2019 ยืดยาวเท่ากับปี 2015 อีกครั้งหลังจากสั้นลงในปี 2016/2018 แปลว่าในภาพรวมทีมที่ิ่วิ่งได้น้อยกว่า median ก็เพิ่มมากขึ้น (แต่ Q4 ปี2019 ดันหดสั้น!! หมายถึงจำนวนทีมที่วิ่งมากกว่ากลุ่มใหญ่ก็มีน้อยลงด้วย) รวมถึง median และ maximum ที่ค่อยๆ ตกลงมาเรื่อยๆ เป็นสัญญาณว่าคนวิ่งผลัดทีมส่วนใหญ่ในปีต่อๆ ไปน่าจะต้องทำการบ้านให้โหดขึ้น เพื่อมาโดนเผาไหม้ในสนาม เพื่อหด Q1 และยืด Q3 Q4 ในปีต่อไปครับ
เห็นมั้ยครับ แค่ดูกราฟ ไม่ต้องใช้ตัวเลขซักตัวก็ได้เรื่องไปคุยกับชาวบ้านระหว่างวิ่ง 10 ชั่วโมงปีหน้าแล้ว
Next EP
น่าจะยาวเกินไป(มาก) ใครอ่านมาถึงตรงนี้ขอชื่นชมความมีเวลาว่างพลังสมาธิเลยครับ ยังไงขอ’ญาตตัดตอนไว้ตรงนี้ก่อน เดี๋ยวตอนหน้าจะชวนขุด dataset เล็กๆ ของเราต่อ รับรองว่าจะได้เจออะไรสนุกๆ กับแชมป์ปี 2019 อย่างพี่ป้อมสัญญา และแชมป์ปี 2018 อย่างพี่จรัญแน่นวลลล~~
ทิ้งท้ายด้วย Code ทั้งหมดอีกรอบ เผื่อ TL;DR
(เดาว่าส่วนใหญ่ปิดทิ้งไปก่อนมาเจอโค้ด :P)
setwd('Data/') # Solo Data temp <- list.files(path="Solo", pattern = "*.csv") temp <- sub("^", "Solo/", temp ) soloFiles = lapply(temp, function(i){ read.csv(i, header=TRUE, stringsAsFactors = FALSE) }) # Team Data temp <- list.files(path="Team", pattern = "*.csv") temp <- sub("^", "Team/", temp ) teamFiles = lapply(temp, function(i){ read.csv(i, header=TRUE, stringsAsFactors = FALSE) }) countBIB <- data.frame(c(length(soloFiles[[1]]$BIB), length(soloFiles[[2]]$BIB), length(soloFiles[[3]]$BIB), length(soloFiles[[4]]$BIB), length(soloFiles[[5]]$BIB))) colnames(countBIB) <- "Year" rownames(countBIB) <- c(2014, 2015, 2016, 2018, 2019) x <- as.numeric(rownames(countBIB)) y <- as.numeric(countBIB$Year) fit <- lm(y~x) co <- coef(fit) plot( y ~ x, xlab="Year", ylab="Runners", pch=16, cex.lab = 0.6, cex.axis = 0.6, ylim=c(200,1000), main="Suanpruek 99 Participants" ) abline(fit, col="blue", lwd=2) text( x, y, y, cex=0.7, col="red", pos = 1 ) head(soloFiles[[1]]) head(soloFiles[[2]]) head(soloFiles[[3]]) head(soloFiles[[4]]) head(soloFiles[[5]]) soloRound.2 <- soloFiles[[2]]$TOTAL.ROUNDS[!is.na(soloFiles[[2]]$TOTAL.ROUNDS)] soloRound.3 <- soloFiles[[3]]$TOTAL.ROUNDS[!is.na(soloFiles[[3]]$TOTAL.ROUNDS)] soloRound.4 <- soloFiles[[4]]$TOTAL.ROUNDS[!is.na(soloFiles[[4]]$TOTAL.ROUNDS)] soloRound.5 <- soloFiles[[5]]$TOTAL.ROUNDS[!is.na(soloFiles[[5]]$TOTAL.ROUNDS)] teamRound.2 <- teamFiles[[2]]$TOTAL.ROUNDS[!is.na(teamFiles[[2]]$TOTAL.ROUNDS)] teamRound.3 <- teamFiles[[3]]$TOTAL.ROUNDS[!is.na(teamFiles[[3]]$TOTAL.ROUNDS)] teamRound.4 <- teamFiles[[4]]$TOTAL.ROUNDS[!is.na(teamFiles[[4]]$TOTAL.ROUNDS)] teamRound.5 <- teamFiles[[5]]$TOTAL.ROUNDS[!is.na(teamFiles[[5]]$TOTAL.ROUNDS)] # Solo # Distribution plot par(mfrow=c(2,2)) hist(soloRound.2, breaks=max(soloRound.2), main = "2015", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(soloRound.3, breaks=max(soloRound.3), main = "2016", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(soloRound.4, breaks=max(soloRound.4), main = "2018", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(soloRound.5, breaks=max(soloRound.5), main = "2019", xlab = "Laps", ylab = "Runners", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") # Deviation plot par(mfrow=c(1,1)) TOTAL.ROUNDS <- list( soloRound.2, soloRound.3, soloRound.4, soloRound.5 ) boxplot( TOTAL.ROUNDS, names = c("2015", "2016", "2018", "2019"), las = 2 ) # Team # Distribution plot par(mfrow=c(2,2)) hist(teamRound.2, breaks=max(teamRound.2), main = "2015", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(teamRound.3, breaks=max(teamRound.3), main = "2016", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(teamRound.4, breaks=max(teamRound.4), main = "2018", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") hist(teamRound.5, breaks=max(teamRound.5), main = "2019", xlab = "Laps", ylab = "Teams", cex.lab=0.8, cex.axis=0.8) abline(v=29, lwd=2, col="red") # Deviation plot par(mfrow=c(1,1)) TOTAL.ROUNDS <- list( teamRound.2, teamRound.3, teamRound.4, teamRound.5 ) boxplot( TOTAL.ROUNDS, names = c("2015", "2016", "2018", "2019"), las = 2 ) |

แม่ฉันต้องได้กินกุ้ง