ความเดิมตอนที่แล้ว
โดนแดดเผาในงานไม่พอ ชีวิตรันทดเหมือนเป็นปีชง ต้องหา data มาดู Histogram ผลงานนักวิ่ง ต่อด้วย Boxplot จะได้เห็นว่าแต่ละปีคนจบเยอะ จบน้อยยังไง หากำแพงระยะ 42km และ 50km ที่เปลี่ยนไปเปลี่ยนมาตามสภาพอากาศและจำนวนคนเจอในประเภทเดี่ยว ลามไปจนเจอค่าเฉลี่ย 12.5 รอบ ต่อผลัด ที่ใช้ตัดตัวทวยเทพประเภททีม
ตอนสุดท้ายนี้ของซีรี่ส์นี้เลยจะขอมองต่ำลึกลงไปอีกหน่อย

โจทย์วันนี้
อยากรู้จักขาประจำสวนพฤกษ์ มาวิ่งซ้ำแล้วซ้ำอีก แล้วคนที่มาซ้ำเนี่ยส่วนใหญ่มี performance ดีขึ้นหรือแย่ลง
นี่คือปรับโจทย์ให้สั้นๆ หน่อย ตอนที่แล้วยาวเกินไปมีคนอ่านบ่น
ก่อนจะเริ่มหาคำตอบ ลองเช็คความพร้อมข้อมูลนิดนึง
หลังจากไล่ดูข้อมูลอีกครั้งก็พบความจริง พร้อมกับอยากสารภาพว่า…
- สถิติแบบทีม แต่ละปีมีการเปลี่ยนชื่อทีมไปมาเยอะมากกกกกกก เหมือนมีธรรมเนียมว่าชมรมที่ส่งทีมจะเปลี่ยนชื่อไปเรื่อยๆ ตามตีมในปีนั้นๆ อย่างเช่น สถาวรรันนิ่ง บ้านครูดิน ส่งปีละเกือบสิบทีม ก็เปลี่ยนเป็นผลไม้บาง ดอกไม้บ้าง หรือนักวิ่งกระทิงเปลี่ยวจากวิศวะลาดกระบังก็ตั้งกันฟรีสไตล์ทุกปี ที่โหดร้ายกับการวิเคราะห์ที่สุดคือทีมที่ใช้ชื่อเดิม แต่เปลี่ยนไปเป็นภาษาไทยบ้างอังกฤษบ้าง.. T^T หมดปัญญาจะ clean data เลยขอเหมาว่าชื่อเขียนไม่เหมือนเดิมก็ไม่เอามาคิดเลยละกัน ง่ายๆ งี้แหละ (หน้ามึนครั้งที่ 1)
พอลองเอาปีที่อยู่ติดกันมา map ดูก็พบว่ามีแค่ไม่เกินห้าทีมเท่านั้นที่ใช้ชื่อเดิมเกือบทุกปี
ทีมที่ใช้ชื่อเดิมและแข็งแกร่งสุด (ตามข้อมูลที่บันทึกไว้) คือทีมจากชมรมภูติอนันต์จำนวนสองทีม ที่ใช้ชื่อเดิม (ภูติอนันต์ 1 กับ 2) ในสองสามปีหลังมานี้ แล้วก็ติด top 10 ทุกปี ด้วยจำนวนรอบเกิน 50 รอบ (ตามค่าเฉลี่ย 12.5 รอบต่อผลัด เท่ากับข้อมูลที่เจอในตอนที่แล้วเป๊ะ) ดังนั้น เมื่อมี sample space เหลือให้สนใจน้อยขนาดนี้… ตอนนี้ก็ขอตัดประเภททีมทั้งหมดทิ้งไปเลย ง่ายๆ งี้แหละ (หน้ามึนครั้งที่ 2) - กลับมาที่สถิติประเภทเดี่ยว คงไม่มีใครเปลี่ยนชื่อตัวเองมาวิ่งทุกปี (เปลี่ยนได้เหรอวะ..) ก็น่าจะหา insight รายบุคคลได้ง่ายๆ สิ
 แบบนั้นชีวิตก็ง่ายเกินไป…
แบบนั้นชีวิตก็ง่ายเกินไป…
ข้อมูลปี 2014-2015 ใช้ชื่อนักวิ่งภาษาอังกฤษ แต่ปีที่เหลือดันเป็นภาษาไทยยยย เลยต้องแยกกลุ่มข้อมูลอีกที ได้เป็น- กลุ่ม 1) 2014-2015 ซึ่งนอกจากชื่อเป็นภาษาอังกฤษแล้ว ปี 2014 ยังมีแค่ rank ไม่มีจำนวนรอบอี๊กกกกก ดังนั้น group นี้ก็ต้องใช้ rank กับชื่อ เป็นข้อมูลสำหรับการ mapping ไปด้วยความจำเป็น
- กลุ่ม 2) 2016-2019 ชื่อนักกีฬาคนไทยเป็นภาษาไทยแล้ว (1) และจำนวนรอบที่แต่ละคนวิ่งได้ก็มีแล้ว (2) ก็จะไม่ใช้ rank แต่ใช้จำนวนรอบไปเลย เพราะ rank บางปีเก็บมาตาม category ไม่ได้เป็น overall … (Dataset ชุดนี้ถือเป็นตัวอย่างของ Inconsistency is Evil ที่แท้ทรู)


ส่อง data เสร็จแล้ว ต่อไปก็ลงมือตัดแบ่งข้อมูลแต่ละชุดออกมาก่อน เผื่อเจอหลุมอะไรอีก จะได้ปะผุง่ายๆ
ตอนนี้จะใช้ library ชื่อ dplyr ขวัญใจสายตัดแต่ง data
การตัด data แต่ละ group จะมี 2 แบบ ให้ตัดปุ๊บเหลือข้อมูลที่สนใจเลย ด้วยวิธีคิด RDBMS แบบ SQL ที่ถนัดกันนั่นเองงง (“ใครไปถนัดกับมึงคุณ” – มีคนคิดในใจ)
- Complete List เก็บชื่อนักวิ่งทั้งหมดในทุกปีมารวมกัน ปีไหนไม่ได้วิ่งก็ปล่อยเป็นช่องว่าง ใช้ full_join หรือภาษา SQL เรียก outer join กลุ่มนี้เอาไว้ดูประกอบสนุกๆ
- Revisit List เก็บเฉพาะนักวิ่งที่มาแล้วมาอีก เอาให้เหลือแค่ list ที่ไม่มีช่องว่างในทุกปี ใช้ inner_join แบบเดียวกับ inner join ในภาษา SQL กลุ่มนี้แหละจะมาตอบคำถามในโจทย์วันนี้
ได้แนวทางแล้วก็ตัดโลด
* ใช้ dataset ที่ import มาจากคราวก่อนได้เลย ไม่โชว์โค้ดส่วนนี้ซ้ำละนะ แต่มี import library เพิ่มนิดหน่อย
library(dplyr) library(ggplot2) library(grid) # Rename columns in 2014-2015 selectedColumns <- c("BIB","TEAM.NAME","RANK","CATEGORY","TOTAL.ROUNDS","OFFICIAL.TIME") colnames(teamData.2014) <- selectedColumns colnames(teamData.2015) <- selectedColumns # Group 1 EN-Name 2014-2015 all.2014.2015 <- full_join(soloData.2014, soloData.2015, by=c("NAME")) all.2014.2015 <- data.frame( "NAME"=all.2014.2015$NAME, "RANK2014"=all.2014.2015$RANK.x, "TOTAL.ROUNDS.2014"=all.2014.2015$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2014"=all.2014.2015$OFFICIAL.TIME.x, "RANK2015"=all.2014.2015$RANK.y, "TOTAL.ROUNDS.2015"=all.2014.2015$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2015"=all.2014.2015$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) # Revisit method 1 revisit.2014.2015 <- inner_join(soloData.2014, soloData.2015, by=c("NAME")) revisit.2014.2015 <- data.frame( "NAME"=revisit.2014.2015$NAME, "RANK2014"=revisit.2014.2015$RANK.x, "TOTAL.ROUNDS.2014"=revisit.2014.2015$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2014"=revisit.2014.2015$OFFICIAL.TIME.x, "RANK2015"=revisit.2014.2015$RANK.y, "TOTAL.ROUNDS.2015"=revisit.2014.2015$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2015"=revisit.2014.2015$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) # Group 2 TH-Name 2016-2019 temp <- full_join(soloData.2016, soloData.2018, by=c("NAME")) temp <- data.frame( "NAME"=temp$NAME, "RANK2016"=temp$RANK.x, "TOTAL.ROUNDS.2016"=temp$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=temp$OFFICIAL.TIME.x, "RANK2018"=temp$RANK.y, "TOTAL.ROUNDS.2018"=temp$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2018"=temp$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) all.2016.2019 <- full_join(temp, soloData.2019, by=c("NAME")) all.2016.2019 <- data.frame( "NAME"=all.2016.2019$NAME, "RANK2016"=all.2016.2019$RANK2016, "TOTAL.ROUNDS.2016"=all.2016.2019$TOTAL.ROUNDS.2016, "OFFICIAL.TIME.2016"=all.2016.2019$OFFICIAL.TIME.2016, "RANK2018"=all.2016.2019$RANK2018, "TOTAL.ROUNDS.2018"=all.2016.2019$TOTAL.ROUNDS.2018, "OFFICIAL.TIME.2018"=all.2016.2019$OFFICIAL.TIME.2018, "RANK2019"=all.2016.2019$RANK, "TOTAL.ROUNDS.2019"=all.2016.2019$TOTAL.ROUNDS, "OFFICIAL.TIME.2019"=all.2016.2019$OFFICIAL.TIME, stringsAsFactors = FALSE ) # Total Revisit method 2 revisit.2016.2019 <- all.2016.2019[complete.cases(all.2016.2019),] # beware of incorrectness/missing rows - unless cherry pick columns revisit.2yr.2016.2018 <- inner_join(soloData.2016, soloData.2018, by=c("NAME")) revisit.2yr.2018.2019 <- inner_join(soloData.2018, soloData.2019, by=c("NAME")) revisit.2yr.2016.2019 <- inner_join(soloData.2016, soloData.2019, by=c("NAME")) revisit.2yr.2016.2018 <- data.frame( "NAME"=revisit.2yr.2016.2018$NAME, "RANK2016"=revisit.2yr.2016.2018$RANK.x, "TOTAL.ROUNDS.2016"=revisit.2yr.2016.2018$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=revisit.2yr.2016.2018$OFFICIAL.TIME.x, "RANK2018"=revisit.2yr.2016.2018$RANK.y, "TOTAL.ROUNDS.2018"=revisit.2yr.2016.2018$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2018"=revisit.2yr.2016.2018$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) revisit.2yr.2018.2019 <- data.frame( "NAME"=revisit.2yr.2018.2019$NAME, "RANK2018"=revisit.2yr.2018.2019$RANK.x, "TOTAL.ROUNDS.2018"=revisit.2yr.2018.2019$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=revisit.2yr.2018.2019$OFFICIAL.TIME.x, "RANK2019"=revisit.2yr.2018.2019$RANK.y, "TOTAL.ROUNDS.2019"=revisit.2yr.2018.2019$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2019"=revisit.2yr.2018.2019$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) revisit.2yr.2016.2019 <- data.frame( "NAME"=revisit.2yr.2016.2019$NAME, "RANK2016"=revisit.2yr.2016.2019$RANK.x, "TOTAL.ROUNDS.2016"=revisit.2yr.2016.2019$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=revisit.2yr.2016.2019$OFFICIAL.TIME.x, "RANK2019"=revisit.2yr.2016.2019$RANK.y, "TOTAL.ROUNDS.2019"=revisit.2yr.2016.2019$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2019"=revisit.2yr.2016.2019$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) # Revisit counting revisit.2yr.2016.2018.NAME <- inner_join(soloData.2016, soloData.2018, by=c("NAME"))$NAME revisit.2yr.2018.2019.NAME <- inner_join(soloData.2018, soloData.2019, by=c("NAME"))$NAME revisit.2yr.2016.2019.NAME <- inner_join(soloData.2016, soloData.2019, by=c("NAME"))$NAME countTable <- data.frame( "count.all.2014.2015" = count(all.2014.2015)$n, "count.revisit.2014.2015" = count(revisit.2014.2015)$n, "count.all.2016.2019" = count(all.2016.2019)$n, "count.revisit.2016.2019" = count(revisit.2016.2019)$n, "count.revisit.2yr.2016.2019" = length(revisit.2yr.2016.2019.NAME), "count.revisit.2yr.2016.2018" = length(revisit.2yr.2016.2018.NAME), "count.revisit.2yr.2018.2019" = length(revisit.2yr.2018.2019.NAME) ) |
ไล่ join แล้วก็ reformat data frame นิดหน่อยตามประเภท group ที่จะใช้
ได้จำนวนคนแต่ละกลุ่มตามนี้

แอบส่อง dataset ดูนิดนึง
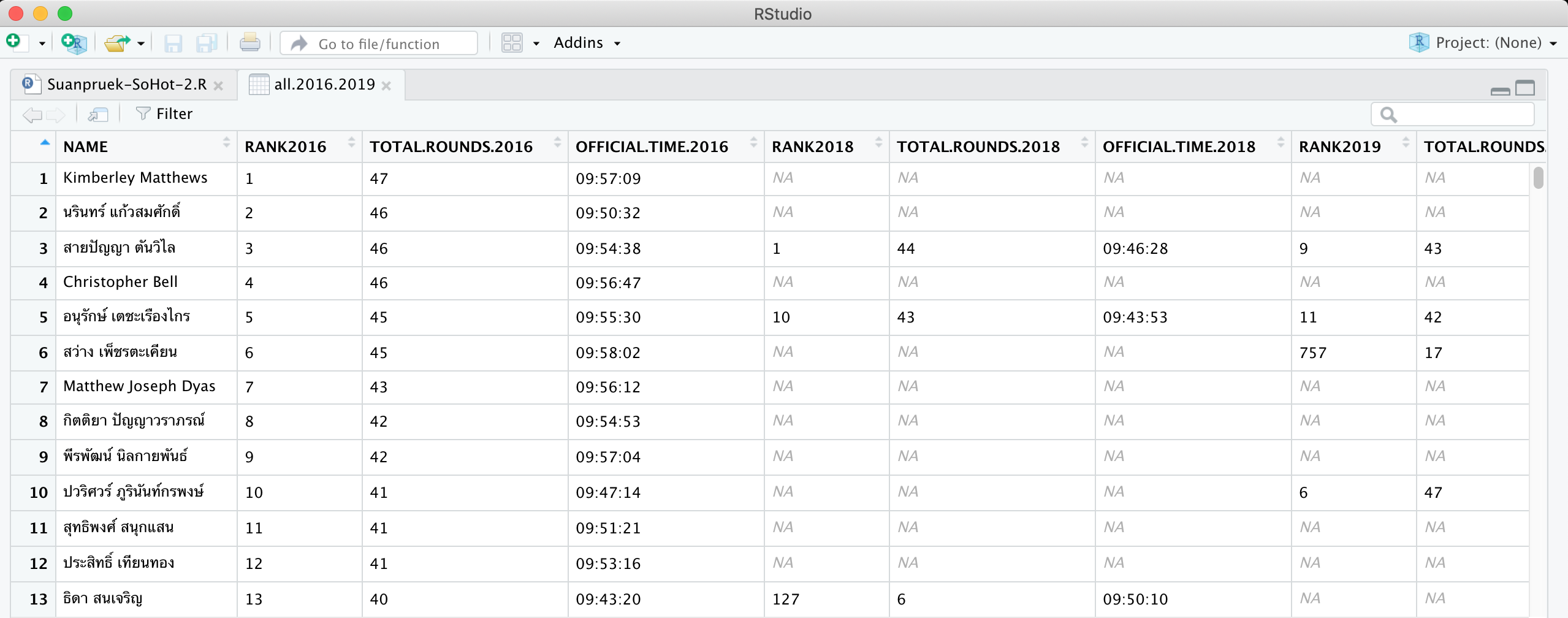
หลุมพรางอันแรกโผล่มาแล้ว…
ช่องว่างใน column TOTAL.ROUNDS หรือจำนวนรอบของนักวิ่งที่ไม่ได้มาทุกปี ที่ตั้งใจปล่อยไว้ ตอนนี้กลายเป็น NA (Not Available) เดี๋ยวพอเอาไปใช้น่าจะมี error อะไรตามมาแหงๆ ตัดไฟแต่ต้นลมด้วยการถมช่องว่างด้วยเลข 0 ซะ เป็นการปิดปัญหาชั้นต้นไปก่อน
# Picking Columns & Fix NA fixed.all.2014.2015 <- data.frame(NAME = all.2014.2015$NAME, RANK2014 = all.2014.2015$RANK2014, RANK2015 = all.2014.2015$RANK2015) fixed.revisit.2014.2015 <- data.frame(NAME = revisit.2014.2015$NAME, RANK2014 = revisit.2014.2015$RANK2014, RANK2015 = revisit.2014.2015$RANK2015) fixed.all.2016.2019 <- data.frame(NAME = all.2016.2019$NAME, TOTAL.ROUNDS.2016 = all.2016.2019$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2018 = all.2016.2019$TOTAL.ROUNDS.2018, TOTAL.ROUNDS.2019 = all.2016.2019$TOTAL.ROUNDS.2019) fixed.revisit.2016.2019 <- data.frame(NAME = revisit.2016.2019$NAME, TOTAL.ROUNDS.2016 = revisit.2016.2019$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2018 = revisit.2016.2019$TOTAL.ROUNDS.2018, TOTAL.ROUNDS.2019 = revisit.2016.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2018 <- data.frame(NAME = revisit.2yr.2016.2018$NAME, TOTAL.ROUNDS.2016 = revisit.2yr.2016.2018$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2018 = revisit.2yr.2016.2018$TOTAL.ROUNDS.2018) fixed.revisit.2yr.2018.2019 <- data.frame(NAME = revisit.2yr.2018.2019$NAME, TOTAL.ROUNDS.2018 = revisit.2yr.2018.2019$TOTAL.ROUNDS.2018, TOTAL.ROUNDS.2019 = revisit.2yr.2018.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2019 <- data.frame(NAME = revisit.2yr.2016.2019$NAME, TOTAL.ROUNDS.2016 = revisit.2yr.2016.2019$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2019 = revisit.2yr.2016.2019$TOTAL.ROUNDS.2019) # Method 1 fixed.all.2014.2015$RANK2014 <- sapply(fixed.all.2014.2015$RANK2014, function(x) { if(is.na(x)) 0 else x }) fixed.all.2014.2015$RANK2015 <- sapply(fixed.all.2014.2015$RANK2015, function(x) { if(is.na(x)) 0 else x }) fixed.revisit.2014.2015$RANK2014 <- sapply(fixed.revisit.2014.2015$RANK2014, function(x) { if(is.na(x)) 0 else x }) fixed.revisit.2014.2015$RANK2015 <- sapply(fixed.revisit.2014.2015$RANK2015, function(x) { if(is.na(x)) 0 else x }) # Method 2 fixed.all.2016.2019$TOTAL.ROUNDS.2016[is.na(fixed.all.2016.2019$TOTAL.ROUNDS.2016)] <- 0 fixed.all.2016.2019$TOTAL.ROUNDS.2018[is.na(fixed.all.2016.2019$TOTAL.ROUNDS.2018)] <- 0 fixed.all.2016.2019$TOTAL.ROUNDS.2019[is.na(fixed.all.2016.2019$TOTAL.ROUNDS.2019)] <- 0 fixed.revisit.2016.2019$TOTAL.ROUNDS.2016[is.na(fixed.revisit.2016.2019$TOTAL.ROUNDS.2016)] <- 0 fixed.revisit.2016.2019$TOTAL.ROUNDS.2018[is.na(fixed.revisit.2016.2019$TOTAL.ROUNDS.2018)] <- 0 fixed.revisit.2016.2019$TOTAL.ROUNDS.2019[is.na(fixed.revisit.2016.2019$TOTAL.ROUNDS.2019)] <- 0 fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016[is.na(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016)] <- 0 fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018[is.na(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018)] <- 0 fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018[is.na(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018)] <- 0 fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019[is.na(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019)] <- 0 fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016[is.na(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016)] <- 0 fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019[is.na(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019)] <- 0 |
จากตอนแรกที่ Group 1 ใช้ rank (มีค่าตั้งแต่ 1 ถึงจำนวนนักวิ่งในปีนั้น) และ Group 2 ใช้จำนวนรอบ (0…50 กว่าๆ) ถึงเวลาต้อง normalize ให้มันเปรียบเทียบเทียบกันได้ขึ้นมาอีกหน่อย…
เอาไงดี.. นึกไปนึกมา ได้วิธีแบบหยาบๆ ก็ map ให้ผลของนักวิ่งแต่ละคนกลายเป็น percentile ของปีนั้นๆ ละกัน ง่ายดี
- ปีไหนใช้ rank ก็เทียบจาก rank ตัวเองต่อ rank ทั้งหมด (อย่าลืม inverse ค่า rank ให้ 1 กลายเป็น maximum ด้วยไม่งั้นผลพลิกเลยนะ)
- ปีไหนใช้จำนวนรอบก็เทียบจำนวนรอบตัวเองกับจำนวนรอบสูงสุด
# normalize internal ranking value # Group 1 reverse ranking ( 1 --> maximum and vise versa ) fixed.revisit.2014.2015$RANK2014 <- sapply(fixed.revisit.2014.2015$RANK2014, function(x) abs(max(fixed.revisit.2014.2015$RANK2014) - x )) fixed.revisit.2014.2015$RANK2015 <- sapply(fixed.revisit.2014.2015$RANK2015, function(x) abs(max(fixed.revisit.2014.2015$RANK2015) - x )) # Normalize # Group 1 Revisit fixed.revisit.2014.2015$RANK2014 <- ecdf(fixed.revisit.2014.2015$RANK2014)(fixed.revisit.2014.2015$RANK2014) fixed.revisit.2014.2015$RANK2015 <- ecdf(fixed.revisit.2014.2015$RANK2015)(fixed.revisit.2014.2015$RANK2015) # Group 1 All fixed.all.2014.2015$RANK2014 <- ecdf(fixed.all.2014.2015$RANK2014)(fixed.all.2014.2015$RANK2014) fixed.all.2014.2015$RANK2015 <- ecdf(fixed.all.2014.2015$RANK2015)(fixed.all.2014.2015$RANK2015) # Group 2 Revisit fixed.revisit.2016.2019$TOTAL.ROUNDS.2016 <- ecdf(fixed.revisit.2016.2019$TOTAL.ROUNDS.2016)(fixed.revisit.2016.2019$TOTAL.ROUNDS.2016) fixed.revisit.2016.2019$TOTAL.ROUNDS.2018 <- ecdf(fixed.revisit.2016.2019$TOTAL.ROUNDS.2018)(fixed.revisit.2016.2019$TOTAL.ROUNDS.2018) fixed.revisit.2016.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.revisit.2016.2019$TOTAL.ROUNDS.2019)(fixed.revisit.2016.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016 <- ecdf(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016)(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016) fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018 <- ecdf(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018)(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018) fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018 <- ecdf(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018)(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018) fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019)(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016 <- ecdf(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016)(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016) fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019)(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019) # Group 2 All fixed.all.2016.2019$TOTAL.ROUNDS.2016 <- ecdf(fixed.all.2016.2019$TOTAL.ROUNDS.2016)(fixed.all.2016.2019$TOTAL.ROUNDS.2016) fixed.all.2016.2019$TOTAL.ROUNDS.2018 <- ecdf(fixed.all.2016.2019$TOTAL.ROUNDS.2018)(fixed.all.2016.2019$TOTAL.ROUNDS.2018) fixed.all.2016.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.all.2016.2019$TOTAL.ROUNDS.2019)(fixed.all.2016.2019$TOTAL.ROUNDS.2019) |
ขอเสนอ ecdf (Empirical Culmulative Distribution Function – ซึ่งก็เพิ่งรู้จักตอนที่อยากเทียบค่าของแต่ละตำแหน่งใน list นี่แหละ) เบื้องหลังลึกๆ มันจะทำงานยังไงช่างมันก่อน (หาอ่านเองได้ไม่ยากอยู่ละ) ตอนนี้แค่รู้ว่ามันจะคืนค่า percentile ของ value แต่ละตัวใน list ที่โยนเข้าไปกลับมาให้เราได้ เช่น ถ้าโยน list [1, 2, 3, 4, 5] เข้าไปใน ecdf ก็จะได้ [0.2, 0.4, 0.6, 0.8, 1.0] พอนึกภาพออกเนอะ
เพื่อความสมบูรณ์แบบ จริงแล้วก็ควรเอา OFFICIAL.TIME มาคิดด้วย.. ใครว่างก็เชิญ ขอทิ้งไว้เป็นแบบฝึกหัดครับ

Visualize กันหน่อย
คิดอยู่นานว่าจะ plot อะไรให้เห็นการว่าแต่ละคนที่มาซ้ำเกินสองปีวิ่งได้ต่างจากเดิมขนาดไหน ปกติในโลก sport performance จะไม่ค่อยเห็นคนทำ bulk แบบนี้ แต่ดูแค่ average กับ trending เหมือนที่เคยทำกันในตอน 1 ก็พอเห็นภาพแล้ว
แต่ก็นั่นแหละ อยากเห็นอะไรสวยๆ ก็ต้องทำต่อไปอีกหน่อย
หลังจากเลือกไม่ได้ว่าจะใช้ plot แบบไหน ก็คืนสู่สามัญ ใช้ line plot ให้เส้นแทนนักวิ่งแต่ละคนผ่าน column แต่ละปีเลย แล้วค่อยมาซูมดูเทรนด์กันอีกที
# Visualization & Intepretation # jitter plot / line plot # Group 1 # revisit df1 <- data.frame(year=2014, rank=fixed.revisit.2014.2015$RANK2014, name=fixed.revisit.2014.2015$NAME) df2 <- data.frame(year=2015, rank=fixed.revisit.2014.2015$RANK2015, name=fixed.revisit.2014.2015$NAME) df.1.revisit <- rbind(df1, df2) # all 2014-2015 df1 <- data.frame(year=2014, rank=fixed.all.2014.2015$RANK2014, name=fixed.all.2014.2015$NAME) df2 <- data.frame(year=2015, rank=fixed.all.2014.2015$RANK2015, name=fixed.all.2014.2015$NAME) df.1.all <- rbind(df1, df2) # Group 2 # revisit every year df1 <- data.frame(year=2016, rank=fixed.revisit.2016.2019$TOTAL.ROUNDS.2016, name=fixed.revisit.2016.2019$NAME) df2 <- data.frame(year=2018, rank=fixed.revisit.2016.2019$TOTAL.ROUNDS.2018, name=fixed.revisit.2016.2019$NAME) df3 <- data.frame(year=2019, rank=fixed.revisit.2016.2019$TOTAL.ROUNDS.2019, name=fixed.revisit.2016.2019$NAME) df.2.revisit <- rbind(df1, df2, df3) # revisit 2016/2018 df1 <- data.frame(year=2016, rank=fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016, name=fixed.revisit.2yr.2016.2018$NAME) df2 <- data.frame(year=2018, rank=fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018, name=fixed.revisit.2yr.2016.2018$NAME) df.2.2016.2018 <- rbind(df1, df2) # revisit 2016/2019 df1 <- data.frame(year=2016, rank=fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016, name=fixed.revisit.2yr.2016.2019$NAME) df2 <- data.frame(year=2019, rank=fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019, name=fixed.revisit.2yr.2016.2019$NAME) df.2.2016.2019 <- rbind(df1, df2) # revisit 2018/2019 df1 <- data.frame(year=2018, rank=fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018, name=fixed.revisit.2yr.2018.2019$NAME) df2 <- data.frame(year=2019, rank=fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019, name=fixed.revisit.2yr.2018.2019$NAME) df.2.2018.2019 <- rbind(df1, df2) # all 2016-2019 df1 <- data.frame(year=2016, rank=fixed.all.2016.2019$TOTAL.ROUNDS.2016, name=fixed.all.2016.2019$NAME) df2 <- data.frame(year=2018, rank=fixed.all.2016.2019$TOTAL.ROUNDS.2018, name=fixed.all.2016.2019$NAME) df3 <- data.frame(year=2019, rank=fixed.all.2016.2019$TOTAL.ROUNDS.2019, name=fixed.all.2016.2019$NAME) df.2.all <- rbind(df1, df2, df3) # factorize years df.1.all$year = factor(df.1.all$year) df.1.revisit$year = factor(df.1.revisit$year) df.2.all$year = factor(df.2.all$year) df.2.revisit$year = factor(df.2.revisit$year) df.2.2016.2018$year = factor(df.2.2016.2018$year) df.2.2018.2019$year = factor(df.2.2018.2019$year) df.2.2016.2019$year = factor(df.2.2016.2019$year) commonTheme <- theme( axis.ticks=element_blank(), axis.title.x=element_blank(), axis.title.y=element_blank(), legend.position="none", plot.background=element_blank() ) p.1.all <- ggplot(data = df.1.all, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.1.revisit <- ggplot(data = df.1.revisit, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.all <- ggplot(data = df.2.all, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.revisit <- ggplot(data = df.2.revisit, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.2016.2018 <- ggplot(data = df.2.2016.2018, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.2018.2019 <- ggplot(data = df.2.2018.2019, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.2016.2019 <- ggplot(data = df.2.2016.2019, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme # Wall plot vplayout <- function(x, y) viewport(layout.pos.row = x, layout.pos.col = y) grid.newpage() pushViewport(viewport(layout = grid.layout(1, 2))) print(p.1.all, vp = vplayout(1, 1)) print(p.2.all, vp = vplayout(1, 2)) grid.newpage() pushViewport(viewport(layout = grid.layout(1, 2))) print(p.1.revisit, vp = vplayout(1, 1)) print(p.2.revisit, vp = vplayout(1, 2)) grid.newpage() pushViewport(viewport(layout = grid.layout(1, 3))) print(p.2.2016.2018, vp = vplayout(1, 1)) print(p.2.2018.2019, vp = vplayout(1, 2)) print(p.2.2016.2019, vp = vplayout(1, 3)) |
ggplot มาอีกแล้ว จะให้สวยกว่านี้ก็น่าจะทำได้ แต่ขี้เกียจ..
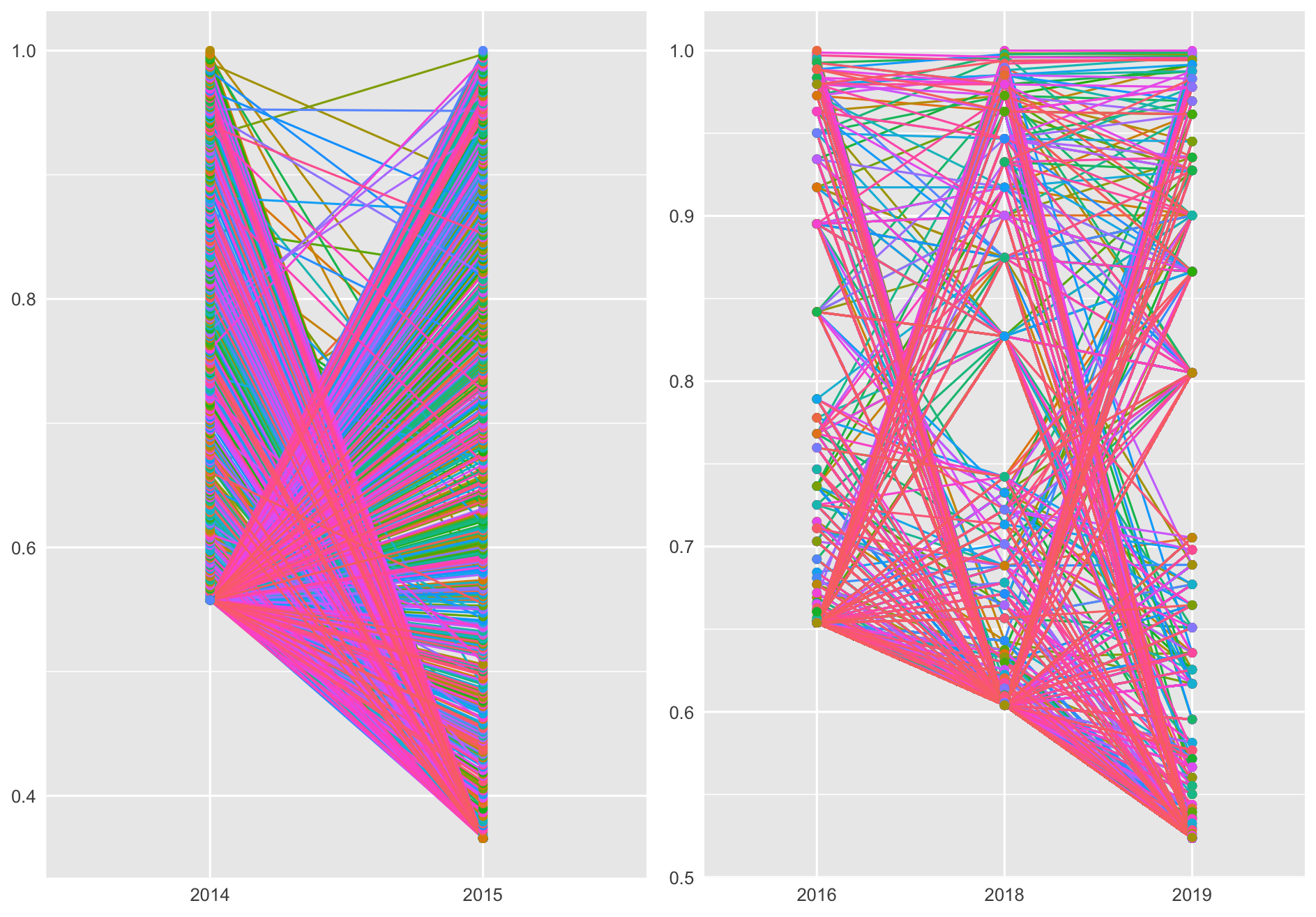
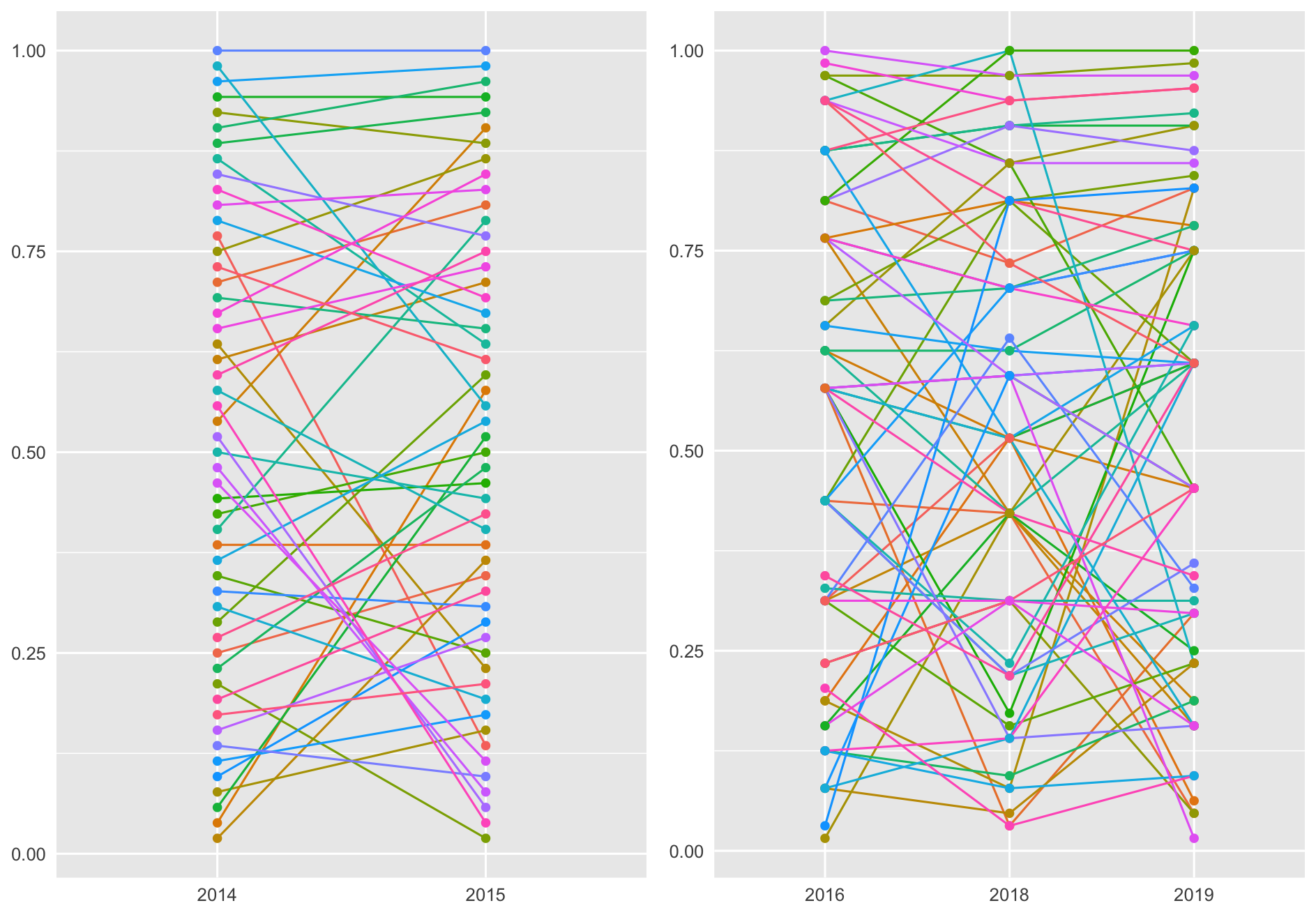
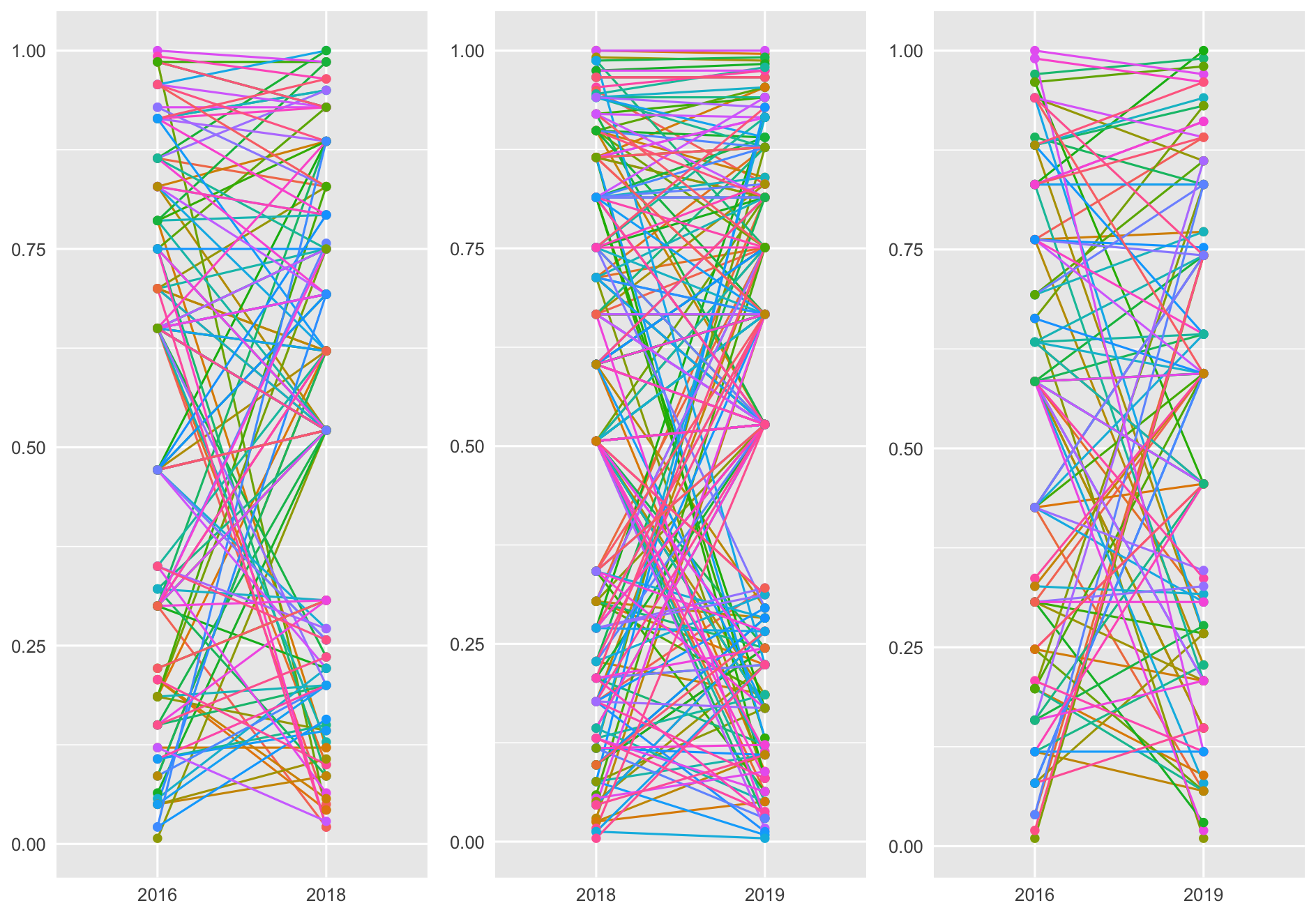
พอลองเอา set อื่นมา plot ด้วย แล้ววางเป็นแผงแบบนี้ก็ดูเป็นงานอาร์ทขึ้นมาเหมือนกัน
สนใจเอาไปปริ้นท์ติดฝาบ้านไว้ชีให้คนอื่นดูว่าตัวเองเป็นเส้นไหนมั้ยครับ? เดี๋ยวทำ high-resolution แจก
บทวิเคราะห์สิงสนามซ้อม
กลุ่มตัวอย่างหลักสิบ-ร้อยต้นๆ ของสวนพฤกษ์ veteran บอกอะไรเราบ้าง?
Group 1) 2014-2015 Revisit
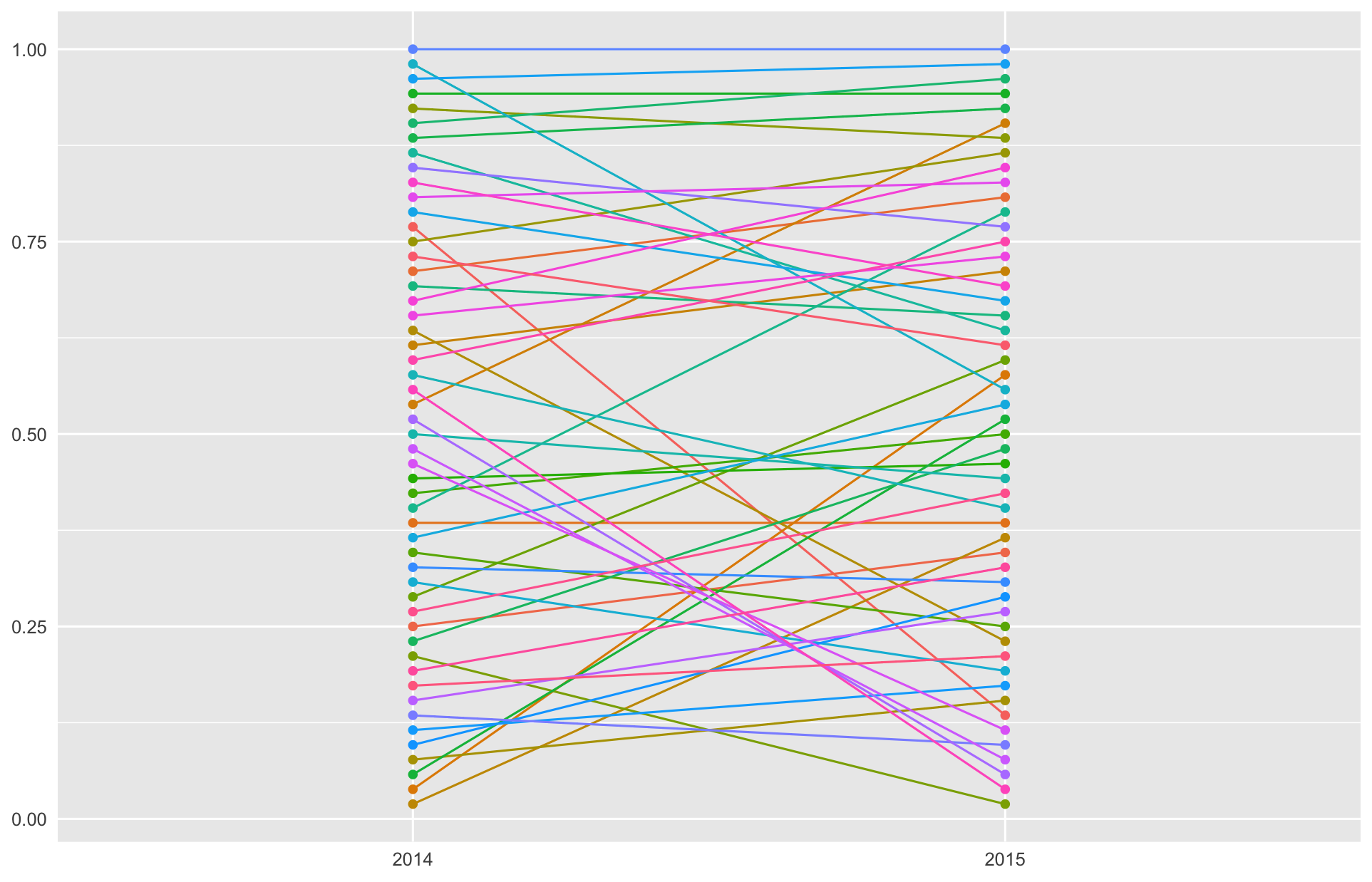
ดูกราฟเร็วๆ จะเห็นว่าคนส่วนมากจะมี relative performance ในปี 2015 พอๆ กับปี 2014
คนที่วิ่งได้จำนวนรอบเปลี่ยนแปลงแบบชัดๆ (กราฟพุ่งขึ้นหรือลงไกลๆ) มีจำนวนพอๆ กันแค่ประมาณ 10 กว่าคน
น่าสังเกตว่า กลุ่มนำก็ยังเป็นกลุ่มนำอยู่ทั้งสองปี มีคนข้ามห้วยมาติดระดับบนๆ ได้ค่อนข้างน้อย
แต่พื้นที่ว่างๆ ตรงกลางนั้นเหมือนจะบอกว่า “นักวิ่งกลางน้ำ” ส่วนใหญ่ในปี 2014 ไม่ค่อยวิ่งได้ระดับเดิมในปี 2015 คือถ้าไม่ดีขึ้นก็จะแย่ลงไปเลย
Group 2) 2016-2019 Revisit
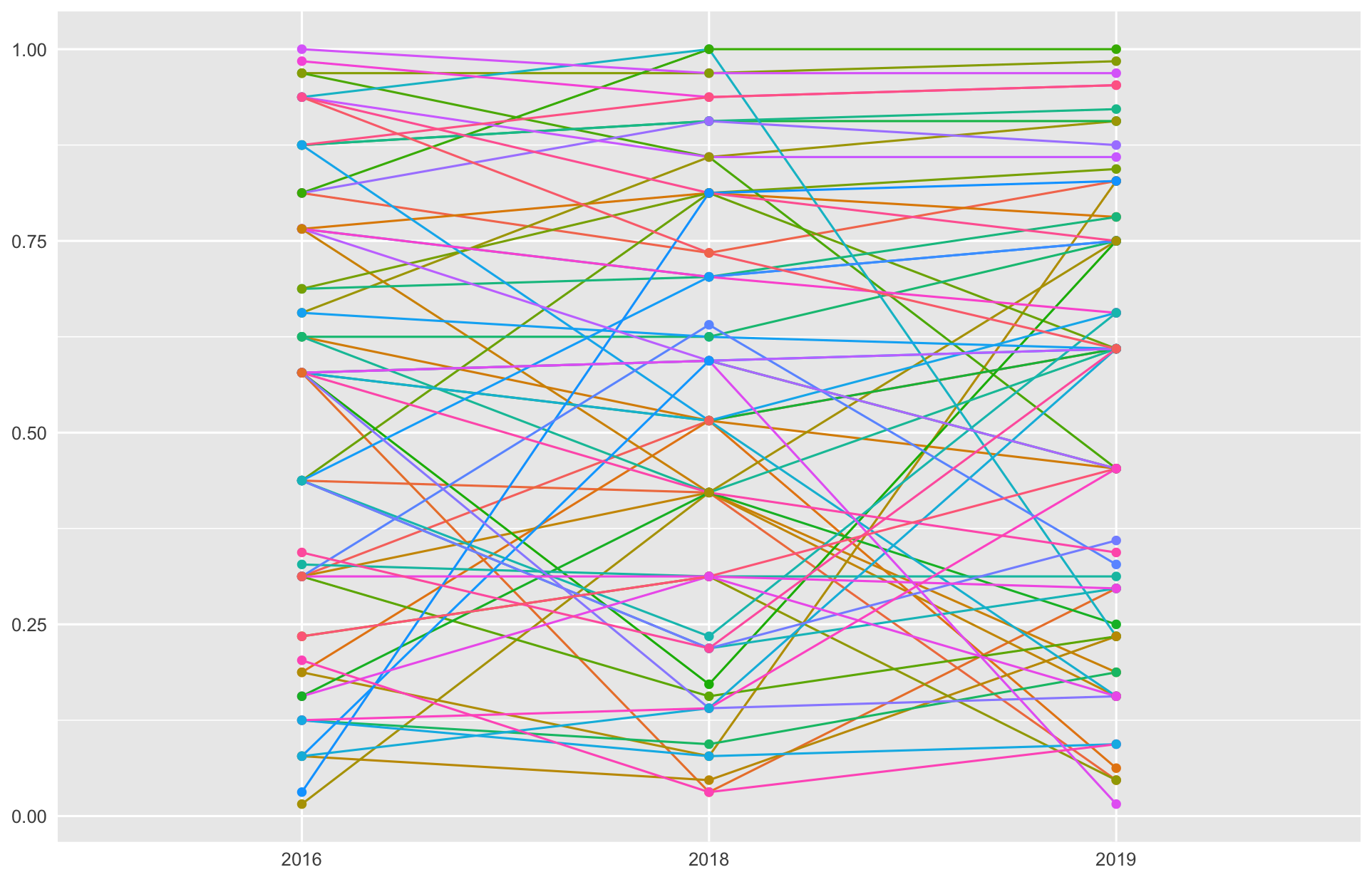
เห็นกราฟครั้งแรกถึงกับอุทานในใจว่า “fluctuate สัส”
anti-pattern ของแท้ เคยได้แชมป์ก็ร่วงไป DNF หรือเคยวิ่งไม่จบก็ดีดตัวเองขึ้นมาจนติด Quartile 4 ได้เหมือนกัน
แต่ละเคสอาจเกิดจากการซ้อมของแต่ละคน ความพร้อมในวันนั้น หรือสภาพอากาศของทุ่งบางกะปิในแต่ละปีก็เดายาก
แต่นอกจากสองกลุ่มนั้นก็ยังมีอีกกลุ่มนึง ที่ยืนระยะรักษามาตรฐานระดับเดิมทุกปี ตัวอย่างกลุ่มนี้ก็เช่น พี่นะ นฤพนธ์ ประธานทิพย์ คนไทยคนแรกๆ ที่ได้เหรียญ six stars จาก Abbott หลังจากวิ่ง world major ครบ 6 รายการ วิ่งได้เกิน 90% มาตั้งแต่ 2016 ถือว่าโหดคงเส้นคงวา หรือคุณสายปัญญา ตันวิไล แชมป์หญิงเดี่ยว 2018 ที่ติด top 10 ทุกปีตั้งแต่ 2014
อีกเรื่องที่น่าสนใจคือ dataset revisit ของทั้ง Group 1 และ Group 2 นั้นไม่ค่อยมีชื่อนักวิ่งต่างชาติที่มาวิ่งครบทุกปี ส่วนนี้น่าหาข้อมูลสถิติเปรียบเทียบ year span ของ expat ที่มาทำงานในไทย เผื่อจะเข้าใจว่านักวิ่งกลุ่มนี้เค้าแค่กลับประเทศหรือคิดได้แล้วว่าอากาศที่ไทยมันร้อนเกินไป เลยเลิกวิ่งแม่ม
Observation
กลับไปขุด dataset อีกอันที่เตรียมไว้แต่ไม่ได้ใช้
complete list นักกีฬาของทั้งสองกรุ๊ปก็มีอะไรน่าส่องอยู่เหมือนกัน
ตามที่”สัญญา”ไว้ มาตามหาพี่ป้อม สัญญา คานชัย กับนักวิ่งดังๆ ในสถิติชุดนี้กันดู
สังเกตว่าต่อให้เป็นงานประจำปีขนาดนี้ก็ไม่ได้แปลว่านักวิ่งระดับ elite หลายๆ คนจะลงทุกปี พี่จรัญที่เป็นแชมป์ปี 2018 ก็เคยวิ่งได้แค่ 19 รอบในปี 2015 และหายไปฝึกวิชาในปี 2016 (พี่จรัญมาวิ่งปี 2014-2015 แต่ดันสะกดนามสกุลไม่เหมือนกัน Poolsawad กับ Poolsawat เลยหายไปจาก dataset หลักที่ใช้.. อย่าโทษผมนะ ให้โทษ data…) พี่ป้อม สัญญา ก็ไม่ได้มาวิ่งปี 2016 หรือ Randy Travis นักวิ่งอัลตร้าชาวอเมริกันยุคบุกเบิกของไทยที่เคยขึ้นไปถึงอันดับสองในปี 2014 ก็มา DQ ในปี 2016 แล้วก็ไม่กลับมาสวนพฤกษ์อีกเลย
การไล่ดู insight นักกีฬารายบุคลคลนี่เหมือนการอ่านหนังสือประวัติศาสตร์ดีๆ เล่มนึงเลยนะครับ แต่ระหว่างบรรทัดนั่นคือชั่วโมงการซ้อมจำนวนมหาศาลกับเหงื่อเป็นลิตรๆ และบทสนทนากับพระเจ้าระหว่างก้าววิ่งที่พวกเราอาจไม่มีวันเข้าถึง

ทิ้งท้าย
ซีรี่ส์สวนพฤกษ์ทั้งสองตอนถือเป็นตัวอย่าง descriptive analysis ที่เอา data มาสับยำขยำขยี้ โดยรวบขั้นตอนให้เห็นตั้งแต่การหา data การทำ data manipulation จนถึงการ review result เจาะเวลาหาอดีตดูว่าผลแต่ละอย่างน่าจะเกิดจากสาเหตุอะไร แต่ก็คงเป็นตัวอย่างที่ไม่ค่อยถูกต้องตามหลักการทำงานกับข้อมูลเท่าไหร่ เรียกว่าทำเอาสนุก ให้ได้ข้อมูลมันๆ ไว้คุยเล่นกับชาวบ้านระหว่างวิ่ง การจะเอาไปอ้างอิงเป็นหลักวิชาการใดๆ นั้นคงไม่ค่อยเหมาะนะครับนะ
ถ้าใครชอบอ่านอะไรยาวๆ เรื่องการวิเคราะห์ข้อมูลจากงานวิ่งแบบตอนนี้ (แต่วิเคราะห์ละเอียดและมีที่มาที่ไปกว่านี้เยอะ) โดยเฉพาะพวกงาน world major ก็ขอแนะนำ blog Running with Data เวลาจบงานนึงก็จะมีวิเคราะห์ให้อ่านกันตาแฉะ เห็นแล้วอิจฉาความมี data ให้เล่นมากมายของพวกงานระดับโลกจริงๆ
วันนี้พอแค่นี้ละ
ไปครับ! ไปวิ่ง!!

แปะ Code ทั้งหมดอีกรอบนึง
library(dplyr) library(ggplot2) library(grid) # Rename columns in 2014-2015 selectedColumns <- c("BIB","TEAM.NAME","RANK","CATEGORY","TOTAL.ROUNDS","OFFICIAL.TIME") colnames(teamData.2014) <- selectedColumns colnames(teamData.2015) <- selectedColumns # Group 1 EN-Name 2014-2015 all.2014.2015 <- full_join(soloData.2014, soloData.2015, by=c("NAME")) all.2014.2015 <- data.frame( "NAME"=all.2014.2015$NAME, "RANK2014"=all.2014.2015$RANK.x, "TOTAL.ROUNDS.2014"=all.2014.2015$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2014"=all.2014.2015$OFFICIAL.TIME.x, "RANK2015"=all.2014.2015$RANK.y, "TOTAL.ROUNDS.2015"=all.2014.2015$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2015"=all.2014.2015$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) # Revisit method 1 revisit.2014.2015 <- inner_join(soloData.2014, soloData.2015, by=c("NAME")) revisit.2014.2015 <- data.frame( "NAME"=revisit.2014.2015$NAME, "RANK2014"=revisit.2014.2015$RANK.x, "TOTAL.ROUNDS.2014"=revisit.2014.2015$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2014"=revisit.2014.2015$OFFICIAL.TIME.x, "RANK2015"=revisit.2014.2015$RANK.y, "TOTAL.ROUNDS.2015"=revisit.2014.2015$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2015"=revisit.2014.2015$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) # Group 2 TH-Name 2016-2019 temp <- full_join(soloData.2016, soloData.2018, by=c("NAME")) temp <- data.frame( "NAME"=temp$NAME, "RANK2016"=temp$RANK.x, "TOTAL.ROUNDS.2016"=temp$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=temp$OFFICIAL.TIME.x, "RANK2018"=temp$RANK.y, "TOTAL.ROUNDS.2018"=temp$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2018"=temp$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) all.2016.2019 <- full_join(temp, soloData.2019, by=c("NAME")) all.2016.2019 <- data.frame( "NAME"=all.2016.2019$NAME, "RANK2016"=all.2016.2019$RANK2016, "TOTAL.ROUNDS.2016"=all.2016.2019$TOTAL.ROUNDS.2016, "OFFICIAL.TIME.2016"=all.2016.2019$OFFICIAL.TIME.2016, "RANK2018"=all.2016.2019$RANK2018, "TOTAL.ROUNDS.2018"=all.2016.2019$TOTAL.ROUNDS.2018, "OFFICIAL.TIME.2018"=all.2016.2019$OFFICIAL.TIME.2018, "RANK2019"=all.2016.2019$RANK, "TOTAL.ROUNDS.2019"=all.2016.2019$TOTAL.ROUNDS, "OFFICIAL.TIME.2019"=all.2016.2019$OFFICIAL.TIME, stringsAsFactors = FALSE ) # Total Revisit method 2 revisit.2016.2019 <- all.2016.2019[complete.cases(all.2016.2019),] # beware of incorrectness/missing rows - unless cherry pick columns revisit.2yr.2016.2018 <- inner_join(soloData.2016, soloData.2018, by=c("NAME")) revisit.2yr.2018.2019 <- inner_join(soloData.2018, soloData.2019, by=c("NAME")) revisit.2yr.2016.2019 <- inner_join(soloData.2016, soloData.2019, by=c("NAME")) revisit.2yr.2016.2018 <- data.frame( "NAME"=revisit.2yr.2016.2018$NAME, "RANK2016"=revisit.2yr.2016.2018$RANK.x, "TOTAL.ROUNDS.2016"=revisit.2yr.2016.2018$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=revisit.2yr.2016.2018$OFFICIAL.TIME.x, "RANK2018"=revisit.2yr.2016.2018$RANK.y, "TOTAL.ROUNDS.2018"=revisit.2yr.2016.2018$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2018"=revisit.2yr.2016.2018$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) revisit.2yr.2018.2019 <- data.frame( "NAME"=revisit.2yr.2018.2019$NAME, "RANK2018"=revisit.2yr.2018.2019$RANK.x, "TOTAL.ROUNDS.2018"=revisit.2yr.2018.2019$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=revisit.2yr.2018.2019$OFFICIAL.TIME.x, "RANK2019"=revisit.2yr.2018.2019$RANK.y, "TOTAL.ROUNDS.2019"=revisit.2yr.2018.2019$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2019"=revisit.2yr.2018.2019$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) revisit.2yr.2016.2019 <- data.frame( "NAME"=revisit.2yr.2016.2019$NAME, "RANK2016"=revisit.2yr.2016.2019$RANK.x, "TOTAL.ROUNDS.2016"=revisit.2yr.2016.2019$TOTAL.ROUNDS.x, "OFFICIAL.TIME.2016"=revisit.2yr.2016.2019$OFFICIAL.TIME.x, "RANK2019"=revisit.2yr.2016.2019$RANK.y, "TOTAL.ROUNDS.2019"=revisit.2yr.2016.2019$TOTAL.ROUNDS.y, "OFFICIAL.TIME.2019"=revisit.2yr.2016.2019$OFFICIAL.TIME.y, stringsAsFactors = FALSE ) # Revisit counting revisit.2yr.2016.2018.NAME <- inner_join(soloData.2016, soloData.2018, by=c("NAME"))$NAME revisit.2yr.2018.2019.NAME <- inner_join(soloData.2018, soloData.2019, by=c("NAME"))$NAME revisit.2yr.2016.2019.NAME <- inner_join(soloData.2016, soloData.2019, by=c("NAME"))$NAME countTable <- data.frame( "count.all.2014.2015" = count(all.2014.2015)$n, "count.revisit.2014.2015" = count(revisit.2014.2015)$n, "count.all.2016.2019" = count(all.2016.2019)$n, "count.revisit.2016.2019" = count(revisit.2016.2019)$n, "count.revisit.2yr.2016.2019" = length(revisit.2yr.2016.2019.NAME), "count.revisit.2yr.2016.2018" = length(revisit.2yr.2016.2018.NAME), "count.revisit.2yr.2018.2019" = length(revisit.2yr.2018.2019.NAME) ) ========================================================================================= # Picking Columns & Fix NA fixed.all.2014.2015 <- data.frame(NAME = all.2014.2015$NAME, RANK2014 = all.2014.2015$RANK2014, RANK2015 = all.2014.2015$RANK2015) fixed.revisit.2014.2015 <- data.frame(NAME = revisit.2014.2015$NAME, RANK2014 = revisit.2014.2015$RANK2014, RANK2015 = revisit.2014.2015$RANK2015) fixed.all.2016.2019 <- data.frame(NAME = all.2016.2019$NAME, TOTAL.ROUNDS.2016 = all.2016.2019$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2018 = all.2016.2019$TOTAL.ROUNDS.2018, TOTAL.ROUNDS.2019 = all.2016.2019$TOTAL.ROUNDS.2019) fixed.revisit.2016.2019 <- data.frame(NAME = revisit.2016.2019$NAME, TOTAL.ROUNDS.2016 = revisit.2016.2019$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2018 = revisit.2016.2019$TOTAL.ROUNDS.2018, TOTAL.ROUNDS.2019 = revisit.2016.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2018 <- data.frame(NAME = revisit.2yr.2016.2018$NAME, TOTAL.ROUNDS.2016 = revisit.2yr.2016.2018$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2018 = revisit.2yr.2016.2018$TOTAL.ROUNDS.2018) fixed.revisit.2yr.2018.2019 <- data.frame(NAME = revisit.2yr.2018.2019$NAME, TOTAL.ROUNDS.2018 = revisit.2yr.2018.2019$TOTAL.ROUNDS.2018, TOTAL.ROUNDS.2019 = revisit.2yr.2018.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2019 <- data.frame(NAME = revisit.2yr.2016.2019$NAME, TOTAL.ROUNDS.2016 = revisit.2yr.2016.2019$TOTAL.ROUNDS.2016, TOTAL.ROUNDS.2019 = revisit.2yr.2016.2019$TOTAL.ROUNDS.2019) # Method 1 fixed.all.2014.2015$RANK2014 <- sapply(fixed.all.2014.2015$RANK2014, function(x) { if(is.na(x)) 0 else x }) fixed.all.2014.2015$RANK2015 <- sapply(fixed.all.2014.2015$RANK2015, function(x) { if(is.na(x)) 0 else x }) fixed.revisit.2014.2015$RANK2014 <- sapply(fixed.revisit.2014.2015$RANK2014, function(x) { if(is.na(x)) 0 else x }) fixed.revisit.2014.2015$RANK2015 <- sapply(fixed.revisit.2014.2015$RANK2015, function(x) { if(is.na(x)) 0 else x }) # Method 2 fixed.all.2016.2019$TOTAL.ROUNDS.2016[is.na(fixed.all.2016.2019$TOTAL.ROUNDS.2016)] <- 0 fixed.all.2016.2019$TOTAL.ROUNDS.2018[is.na(fixed.all.2016.2019$TOTAL.ROUNDS.2018)] <- 0 fixed.all.2016.2019$TOTAL.ROUNDS.2019[is.na(fixed.all.2016.2019$TOTAL.ROUNDS.2019)] <- 0 fixed.revisit.2016.2019$TOTAL.ROUNDS.2016[is.na(fixed.revisit.2016.2019$TOTAL.ROUNDS.2016)] <- 0 fixed.revisit.2016.2019$TOTAL.ROUNDS.2018[is.na(fixed.revisit.2016.2019$TOTAL.ROUNDS.2018)] <- 0 fixed.revisit.2016.2019$TOTAL.ROUNDS.2019[is.na(fixed.revisit.2016.2019$TOTAL.ROUNDS.2019)] <- 0 fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016[is.na(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016)] <- 0 fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018[is.na(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018)] <- 0 fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018[is.na(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018)] <- 0 fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019[is.na(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019)] <- 0 fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016[is.na(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016)] <- 0 fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019[is.na(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019)] <- 0 ========================================================================================= # normalize internal ranking value # Group 1 reverse ranking ( 1 --> maximum and vise versa ) fixed.revisit.2014.2015$RANK2014 <- sapply(fixed.revisit.2014.2015$RANK2014, function(x) abs(max(fixed.revisit.2014.2015$RANK2014) - x )) fixed.revisit.2014.2015$RANK2015 <- sapply(fixed.revisit.2014.2015$RANK2015, function(x) abs(max(fixed.revisit.2014.2015$RANK2015) - x )) # Normalize # Group 1 Revisit fixed.revisit.2014.2015$RANK2014 <- ecdf(fixed.revisit.2014.2015$RANK2014)(fixed.revisit.2014.2015$RANK2014) fixed.revisit.2014.2015$RANK2015 <- ecdf(fixed.revisit.2014.2015$RANK2015)(fixed.revisit.2014.2015$RANK2015) # Group 1 All fixed.all.2014.2015$RANK2014 <- ecdf(fixed.all.2014.2015$RANK2014)(fixed.all.2014.2015$RANK2014) fixed.all.2014.2015$RANK2015 <- ecdf(fixed.all.2014.2015$RANK2015)(fixed.all.2014.2015$RANK2015) # Group 2 Revisit fixed.revisit.2016.2019$TOTAL.ROUNDS.2016 <- ecdf(fixed.revisit.2016.2019$TOTAL.ROUNDS.2016)(fixed.revisit.2016.2019$TOTAL.ROUNDS.2016) fixed.revisit.2016.2019$TOTAL.ROUNDS.2018 <- ecdf(fixed.revisit.2016.2019$TOTAL.ROUNDS.2018)(fixed.revisit.2016.2019$TOTAL.ROUNDS.2018) fixed.revisit.2016.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.revisit.2016.2019$TOTAL.ROUNDS.2019)(fixed.revisit.2016.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016 <- ecdf(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016)(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016) fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018 <- ecdf(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018)(fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018) fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018 <- ecdf(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018)(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018) fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019)(fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019) fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016 <- ecdf(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016)(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016) fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019)(fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019) # Group 2 All fixed.all.2016.2019$TOTAL.ROUNDS.2016 <- ecdf(fixed.all.2016.2019$TOTAL.ROUNDS.2016)(fixed.all.2016.2019$TOTAL.ROUNDS.2016) fixed.all.2016.2019$TOTAL.ROUNDS.2018 <- ecdf(fixed.all.2016.2019$TOTAL.ROUNDS.2018)(fixed.all.2016.2019$TOTAL.ROUNDS.2018) fixed.all.2016.2019$TOTAL.ROUNDS.2019 <- ecdf(fixed.all.2016.2019$TOTAL.ROUNDS.2019)(fixed.all.2016.2019$TOTAL.ROUNDS.2019) ========================================================================================= # Visualization & Intepretation # jitter plot / line plot # Group 1 # revisit df1 <- data.frame(year=2014, rank=fixed.revisit.2014.2015$RANK2014, name=fixed.revisit.2014.2015$NAME) df2 <- data.frame(year=2015, rank=fixed.revisit.2014.2015$RANK2015, name=fixed.revisit.2014.2015$NAME) df.1.revisit <- rbind(df1, df2) # all 2014-2015 df1 <- data.frame(year=2014, rank=fixed.all.2014.2015$RANK2014, name=fixed.all.2014.2015$NAME) df2 <- data.frame(year=2015, rank=fixed.all.2014.2015$RANK2015, name=fixed.all.2014.2015$NAME) df.1.all <- rbind(df1, df2) # Group 2 # revisit every year df1 <- data.frame(year=2016, rank=fixed.revisit.2016.2019$TOTAL.ROUNDS.2016, name=fixed.revisit.2016.2019$NAME) df2 <- data.frame(year=2018, rank=fixed.revisit.2016.2019$TOTAL.ROUNDS.2018, name=fixed.revisit.2016.2019$NAME) df3 <- data.frame(year=2019, rank=fixed.revisit.2016.2019$TOTAL.ROUNDS.2019, name=fixed.revisit.2016.2019$NAME) df.2.revisit <- rbind(df1, df2, df3) # revisit 2016/2018 df1 <- data.frame(year=2016, rank=fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2016, name=fixed.revisit.2yr.2016.2018$NAME) df2 <- data.frame(year=2018, rank=fixed.revisit.2yr.2016.2018$TOTAL.ROUNDS.2018, name=fixed.revisit.2yr.2016.2018$NAME) df.2.2016.2018 <- rbind(df1, df2) # revisit 2016/2019 df1 <- data.frame(year=2016, rank=fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2016, name=fixed.revisit.2yr.2016.2019$NAME) df2 <- data.frame(year=2019, rank=fixed.revisit.2yr.2016.2019$TOTAL.ROUNDS.2019, name=fixed.revisit.2yr.2016.2019$NAME) df.2.2016.2019 <- rbind(df1, df2) # revisit 2018/2019 df1 <- data.frame(year=2018, rank=fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2018, name=fixed.revisit.2yr.2018.2019$NAME) df2 <- data.frame(year=2019, rank=fixed.revisit.2yr.2018.2019$TOTAL.ROUNDS.2019, name=fixed.revisit.2yr.2018.2019$NAME) df.2.2018.2019 <- rbind(df1, df2) # all 2016-2019 df1 <- data.frame(year=2016, rank=fixed.all.2016.2019$TOTAL.ROUNDS.2016, name=fixed.all.2016.2019$NAME) df2 <- data.frame(year=2018, rank=fixed.all.2016.2019$TOTAL.ROUNDS.2018, name=fixed.all.2016.2019$NAME) df3 <- data.frame(year=2019, rank=fixed.all.2016.2019$TOTAL.ROUNDS.2019, name=fixed.all.2016.2019$NAME) df.2.all <- rbind(df1, df2, df3) # factorize years df.1.all$year = factor(df.1.all$year) df.1.revisit$year = factor(df.1.revisit$year) df.2.all$year = factor(df.2.all$year) df.2.revisit$year = factor(df.2.revisit$year) df.2.2016.2018$year = factor(df.2.2016.2018$year) df.2.2018.2019$year = factor(df.2.2018.2019$year) df.2.2016.2019$year = factor(df.2.2016.2019$year) commonTheme <- theme( axis.ticks=element_blank(), axis.title.x=element_blank(), axis.title.y=element_blank(), legend.position="none", plot.background=element_blank() ) p.1.all <- ggplot(data = df.1.all, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.1.revisit <- ggplot(data = df.1.revisit, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.all <- ggplot(data = df.2.all, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.revisit <- ggplot(data = df.2.revisit, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.2016.2018 <- ggplot(data = df.2.2016.2018, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.2018.2019 <- ggplot(data = df.2.2018.2019, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme p.2.2016.2019 <- ggplot(data = df.2.2016.2019, aes(x=year, y=rank, group = name, colour = name)) + geom_line() + geom_point() + commonTheme # Wall plot vplayout <- function(x, y) viewport(layout.pos.row = x, layout.pos.col = y) grid.newpage() pushViewport(viewport(layout = grid.layout(1, 2))) print(p.1.all, vp = vplayout(1, 1)) print(p.2.all, vp = vplayout(1, 2)) grid.newpage() pushViewport(viewport(layout = grid.layout(1, 2))) print(p.1.revisit, vp = vplayout(1, 1)) print(p.2.revisit, vp = vplayout(1, 2)) grid.newpage() pushViewport(viewport(layout = grid.layout(1, 3))) print(p.2.2016.2018, vp = vplayout(1, 1)) print(p.2.2018.2019, vp = vplayout(1, 2)) print(p.2.2016.2019, vp = vplayout(1, 3)) |

แม่ฉันต้องได้กินกุ้ง